Multi-cluster Networking with Service Mesh in GKE

This is the seventh post in a series exploring the features of GKE Enterprise, formerly known as Anthos. GKE Enterprise is an additional subscription service for GKE that adds configuration and policy management, service mesh and other features to support running Kubernetes workloads in Google Cloud, on other clouds and even on-premises. If you missed the first post, you might want to start there.
In this post we’ll continue our journey into the wonderful world of Cloud Service Mesh by exploring how we extend a mesh across multiple clusters, including clusters in different subnets, projects and even clouds! So far, we’ve discussed several scenarios where running multiple clusters can be beneficial, above and beyond simple scalability and high availability. Often there are requirements for elements of a workload stack to run in a specific geographic location, and even on specific hardware on-premises. GKE Enterprise allows us to manage clusters that run on our own hardware, and combining this approach with a service mesh allows us to also leverage things like service discovery and secure microservices in a true hybrid cloud environment.
Cloud Service Mesh provides multi-cluster capabilities and endpoint discovery across GKE clusters in Google Cloud automatically, but extending this approach to managed GKE clusters in other clouds and attached Kubernetes clusters on-premises presents some new challenges. Building on the foundational service mesh topics we covered in the last post, we’ll add these multi-cluster scenarios to our tool belt, before approaching service mesh security in my next post. After that, you’ll have all the knowledge you need to know if service mesh is right for your workloads.
So, in this post, we’ll cover the following topics:
Understanding the different operating modes of Cloud Service Mesh
Setting up service mesh discovery across multiple clusters
Extending service mesh outside of Google Cloud
Just like in previous posts, I’ll also walk through a working example so you can see how all the pieces fit together.
Types of multi-cluster mesh
Google’s Cloud Service Mesh supports several modes of installation and operation, with varying levels of complexity:
Managed Multi-Cluster Mesh on Google Cloud: This is the most straightforward option and works almost completely “out of the box”, leveraging Cloud Service Mesh as a fully managed service and providing endpoint discovery between all GKE clusters inside Google Cloud. Clusters can exist in the same project or in different projects, providing they run on the same VPC network and in the same fleet. Shared VPC can be used to manage multi-project networking.
In-Cluster Mesh inside Google Cloud: This option uses the
asmclitool to install the Istio control plane directly into your clusters. It gives you complete control over all service mesh components, but this means you can no longer rely on Cloud Service Mesh as a managed service; you will need to maintain and update the Istio components yourself. In-Cluster Mesh is no longer recommended for clusters running inside Google Cloud, except for in outlier use cases.In-Cluster Mesh outside Google Cloud: Using the
asmclitool you can also install Cloud Service Mesh in its non-managed form on GKE clusters running in VMWare, Azure, AWS and even bare metal. Rather than install Istio from scratch, using the In-Cluster mesh service still allows you to observe your mesh through the Google Cloud console, and provides some additional assistance with things like east-west gateways.
The limitation of each of these approaches is that the multi-cluster mesh will only extend to additional clusters in the same environment. A true hybrid mesh would allow the same service mesh installation to extend across your Google Cloud projects, other clouds and even into your own datacenter. At the time of writing, hybrid mesh is still in preview and is not supported by Google. However, we will briefly cover this approach at the end of the post.
Meshing clusters within Google Cloud
Meshing two or more GKE clusters within Google Cloud is supported by default with Cloud Service Mesh. The main prerequisites for service mesh are that all clusters belong to the same fleet, and that connectivity between all Pods in all clusters is allowed. This can be achieved in one of two ways:
Clusters in the same project on the same network
Clusters in different project sharing the same network via Shared VPC
There are some additional considerations for clusters in different subnets in a VPC, and private clusters, but we’ll cover those later on. For now, let’s walk through a basic multi-cluster mesh example.
To try out a multi-cluster mesh, we just need to ensure that Cloud Service Mesh is enabled for our fleet, and then create 2 GKE clusters, ensuring that they are registered to the fleet at the time of creation (we covered how to set this up in the last post).
In the following steps we’ll refer to these clusters as cluster-1 and cluster-2. If you’re following along, make sure the output of gcloud container fleet mesh describe shows that everything in your mesh is ready to go.
Testing the mesh with a sample app
To test the cross-cluster mesh, we’ll deploy a very basic Hello World application to both clusters. The app will expose a service that replies with “Hello World”, but with a different version number for each cluster so we can trace which cluster serves the request. Because we now have multi-cluster service discovery, the Service object we call will automatically include Pods from both clusters in its endpoints!
Because we’re going to be running commands on two clusters in this walkthrough, we’re going to employ some handy tricks:
We’ll write YAML manifest files that contain multiple objects, so we’ll use
-lto specify that only the objects that match specific labels should be created.We’ll be using the
--contextoption withkubectlto specify which cluster to apply to. You should already have two contexts set up in yourkubeconfigfor your clusters, but you can rename them to something more convenient likecluster-1andcluster-2usingkubectl config rename-context.
So, the first thing to do is create a namespace for our app and label it for Istio’s automatic sidecar injection. Using the tricks above, we’ll do this for both clusters:
kubectl --context=cluster-1 create ns sample
kubectl --context=cluster-1 label namespace sample istio-injection=enabled
kubectl --context=cluster-2 create ns sample
kubectl --context=cluster-2 label namespace sample istio-injection=enabled
Now let’s create the helloworld.yaml file that contains the Deployment and Service definitions we need:
apiVersion: v1
kind: Service
metadata:
name: helloworld
labels:
app: helloworld
service: helloworld
spec:
ports:
- port: 5000
name: http
selector:
app: helloworld
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: helloworld-v1
labels:
app: helloworld
version: v1
spec:
replicas: 1
selector:
matchLabels:
app: helloworld
version: v1
template:
metadata:
labels:
app: helloworld
version: v1
spec:
containers:
- name: helloworld
image: docker.io/istio/examples-helloworld-v1:1.0
resources:
requests:
cpu: "100m"
imagePullPolicy: IfNotPresent #Always
ports:
- containerPort: 5000
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: helloworld-v2
labels:
app: helloworld
version: v2
spec:
replicas: 1
selector:
matchLabels:
app: helloworld
version: v2
template:
metadata:
labels:
app: helloworld
version: v2
spec:
containers:
- name: helloworld
image: docker.io/istio/examples-helloworld-v2:1.0
resources:
requests:
cpu: "100m"
imagePullPolicy: IfNotPresent #Always
ports:
- containerPort: 5000
Using this file and our labels trick, we’ll first create the Service object we need on both clusters:
kubectl create --context=cluster-1 -l service=helloworld -n sample -f helloworld.yaml
kubectl create --context=cluster-2 -l service=helloworld -n sample -f helloworld.yaml
And now the Deployment objects. Note that we create a different version on each cluster:
kubectl create --context=cluster-1 -l version=v1 -n sample -f helloworld.yaml
kubectl create --context=cluster-2 -l version=v2 -n sample -f helloworld.yaml
Try using the --context method to check the Service and Deployment objects on both clusters, as well as listing the running Pods. You should see that each Pod has two containers, as the sidecar proxies have been injected.
At this point we’ve got our sample app deployed, but how do we test it? In the next step we’ll create a simple Deployment that we can use to make some in-cluster requests to our newly deployed service. If we make repetitive requests, we should hopefully see the responses getting balanced across both clusters.
In sleep.yaml we essentially create a dummy application that just gives us an in-cluster environment for us to run curl commands and other network tests:
apiVersion: v1
kind: ServiceAccount
metadata:
name: sleep
---
apiVersion: v1
kind: Service
metadata:
name: sleep
labels:
app: sleep
service: sleep
spec:
ports:
- port: 80
name: http
selector:
app: sleep
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sleep
spec:
replicas: 1
selector:
matchLabels:
app: sleep
template:
metadata:
labels:
app: sleep
spec:
terminationGracePeriodSeconds: 0
serviceAccountName: sleep
containers:
- name: sleep
image: curlimages/curl
command: ["/bin/sleep", "infinity"]
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /etc/sleep/tls
name: secret-volume
volumes:
- name: secret-volume
secret:
secretName: sleep-secret
optional: true
Now deploy the app to both clusters:
kubectl apply --context=cluster-1 -n sample -f sleep.yaml
kubectl apply --context=cluster-2 -n sample -f sleep.yaml
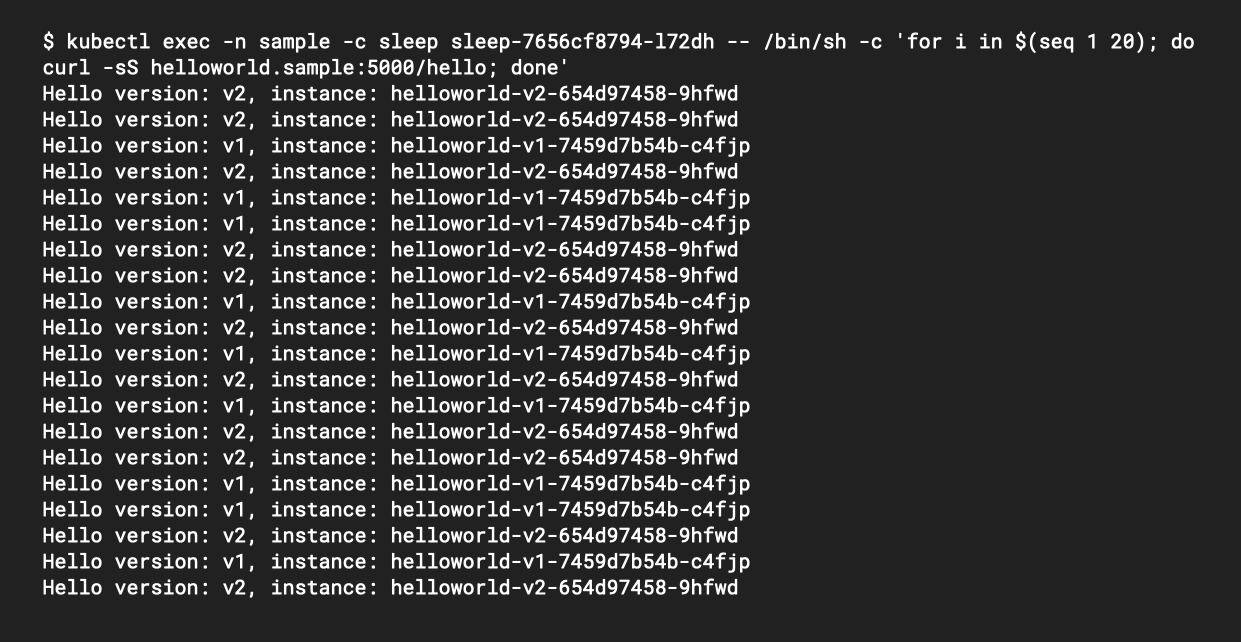
We can now execute a command within the sleep container to test the Hello World application. You can run this test from either cluster, but for simplicity we won’t specify a context in the command examples below.
First, we get the name of a sleep Pod:
kubectl get pod -n sample -l app=sleep
Now we can use that Pod to execute a loop of curl commands to access the Hello World service. In the following example, replace <POD_NAME> with the Pod name you grabbed from the previous command:
kubectl exec -n sample -c sleep <POD_NAME> \
-- /bin/sh -c 'for i in $(seq 1 20); do curl -sS helloworld.sample:5000/hello; done'
You should see 20 responses, roughly distributed across both clusters. Once again, Pods from either cluster (represented by versions 1 and 2) will match endpoints for the service. Multi-cluster mesh and service discovery in action!
Exposing a meshed service to a load balancer
We can take what we learned in our previous post and expose a multi-cluster service via a service mesh VirtualService and a Gateway. However, bear in mind that in this scenario, the Pods running the ingress itself will still only run in a single cluster (we’ll sum up multi-cluster load-balancing options later on).
First, we need to install the Istio ingress gateway Deployment. Recall from my previous post that these are the standalone envoy proxies running at the edge of our cluster. The easiest way to do this is to use the manifests provided by Google in this repo: https://github.com/GoogleCloudPlatform/anthos-service-mesh-packages.git
Let’s create a dedicated namespace for the ingress gateway, and label it for sidecar injection. We only need to do this on cluster-1 for this example, so set your kubectl context appropriately.
kubectl create ns gateway-ns
kubectl label namespace gateway-ns istio-injection=enabled
From the git repo directory, navigate to samples/gateways, where you should find a directory called istio-ingressgateway. This contains manifests for the Deployment, along with the other supporting objects we need. Deploy it to your cluster with this command:
kubectl -n gateway-ns apply -f istio-ingressgateway/
With our ingress Pods running, we can now configure the Gateway and VirtualService objects. Remember that the Gateway object defines how the ingress gateway Pods should be configured, including information such as hosts, protocols and ports. The VirtualService object will then define the routes that our gateway should use, mapping traffic from our gateway to our backend services.
First we’ll create the sample-gateway.yaml object and apply it to cluster-1:
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: frontend-gateway
namespace: sample
spec:
selector:
istio: ingressgateway
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "*"
Then we create the sample-virtualservice.yaml object and also apply it to cluster-1:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: frontend-ingress
namespace: sample
spec:
hosts:
- "*"
gateways:
- frontend-gateway
http:
- route:
- destination:
host: helloworld
port:
number: 5000
Our multi-cluster meshed service is now exposed to the world via a Cloud Load Balancer! To test requests, you can find the external IP by listing the services in the gateway-ns namespace:
kubectl -n gateway-ns get svc
Then just hit http://<EXTERNAL-IP>/hello in your browser, substituting <EXTERNAL-IP> for the IP address you noted from the previous command. You should see the Hello World app respond, and if you keep reloading the page you’ll get responses from version 1 (on cluster 1) and version 2 (on cluster 2).
Considering other options for multi-cluster load balancing
So far, we’ve walked through a simple demonstration to help learn the concepts of service mesh in a multi-cluster environment, but we’ve still arrived at an environment where ingress is dependent on a single cluster. This is not going to be suitable for many production use-cases, so where do we go from here?
There are a few different options to choose from for a multi-cluster approach to load balancing that does not require a single point of failure. For extensive details on each you can refer to the documentation here: https://cloud.google.com/kubernetes-engine/docs/concepts/choose-mc-lb-api
The recommended option is to use a Multi-Cluster Gateway. In the example we’ve just set up, our single-cluster gateway simply exposes an external service, connecting itself to a Cloud Load Balancer, but the gateway is an on-cluster resource.
However, as I covered in a previous post, we can leverage the GKE Gateway Controller to provide a fully managed off-cluster controller than interacts with our Gateway classes, VirtualServices and HTTPRoutes, while providing reliable and highly available cross-cluster load balancing. The GKE Controller works with both Standard and Autopilot clusters, and it simply provides a management layer over standard open-source Kubernetes objects, rather than requiring any proprietary implementation.
Another alternative is the GKE Multi Cluster Ingress controller. This controller also runs off-cluster as a managed service, but it requires less configuration by simply leveraging the MultiClusterService object. However, that means it doesn’t support all the advanced features of the Gateway API we’ve learned about.
The final option is to configure your own Network Endpoint Groups (NEGs) for Cloud Load Balancers. This is an advanced option as it will require the use of Terraform and the Config Connector to automate the assignment of Pod IPs to Load Balancer backends. This might be a useful option for outlier use cases such as combining backends from GKE clusters with serverless workloads, private endpoints or hybrid cloud endpoints in the same load balancer. As always, the best way forward is to consider exactly what your use case is and make your design choices based on exactly what your use case needs to achieve. The simplest choice may often be the best but try to consider if you may need additional features in the future!
Using clusters in different subnets
In the example we walked through, all nodes in our clusters existed on the same VPC subnet. By default, GKE will create firewall rules that allow traffic between nodes on the same subnet, so in this scenario no additional firewall configuration is required. However, in many cases you will be using different subnets, and you must create these rules yourself.
It’s recommended to allow all ports between your cluster nodes on their internal IP addresses. We can achieve this by simply adding a firewall rule to the VPC. However, we will need lists of all subnet CIDRs and network tags used by our nodes. We can do some Bash trickery to obtain these lists and store them in variables, which we’ll use in a moment:
function join_by { local IFS="$1"; shift; echo "$*"; }
ALL_CLUSTER_CIDRS=$(gcloud container clusters list --project $PROJECT_1 --format='value(clusterIpv4Cidr)' | sort | uniq)
ALL_CLUSTER_CIDRS=$(join_by , $(echo "${ALL_CLUSTER_CIDRS}"))
ALL_CLUSTER_NETTAGS=$(gcloud compute instances list --project $PROJECT_1 --format='value(tags.items.[0])' | sort | uniq)
ALL_CLUSTER_NETTAGS=$(join_by , $(echo "${ALL_CLUSTER_NETTAGS}"))
Now we have the ALL_CLUSTER_CIDRS and ALL_CLUSTER_NETTAGS variables populated, we can run the following command to create a firewall rule called isitio-multicluster-pods. You’ll just need to substitute YOUR_VPC with the name of your VPC network:
gcloud compute firewall-rules create istio-multicluster-pods \
--allow=tcp,udp,icmp,esp,ah,sctp \
--direction=INGRESS \
--priority=900 \
--source-ranges="${ALL_CLUSTER_CIDRS}" \
--target-tags="${ALL_CLUSTER_NETTAGS}" --quiet \
--network=YOUR_VPC
All your Pods will now have free-flowing communication between clusters, providing the underlying VPC routes support the connections.
Considerations for private clusters
If you are using private GKE clusters, you will not have public endpoints that can be accessed by the service mesh control plane. This means you have quite a few more hoops to jump through to get a multi-cluster mesh working. The instructions are quite complex, so rather than list them all here I will simply discuss them so you understand what they accomplish, then point you at the Google Cloud documentation page that will build the necessary commands for you.
At a high level:
You will first need to configure endpoint discovery. This involves manually creating remote secrets to represent the private IPs of the cluster (because public IPs are not available). You will then need to apply each cluster’s secrets to the other clusters.
Then you will need to configure authorised networks for the private clusters. This will involve getting the CIDR ranges used for Pods from each cluster and adding them as authorized networks to other clusters.
Just to make this process even trickier, these instructions are detailed across multiple pages of documentation! The instructions for endpoint discovery can be found here: https://cloud.google.com/service-mesh/docs/operate-and-maintain/multi-cluster#endpoint-discovery-declarative-api and the instructions for opening ports on private clusters can be found here: https://cloud.google.com/service-mesh/docs/operate-and-maintain/private-cluster-open-port
A final consideration for private clusters is that they will not, by default, have access to the Internet to download the container images from Docker Hub that we have used in this post. To solve this, you can either manually download and add container images to Google’s Artifact Registry or configure a Cloud NAT connection for Internet access.
Using Cloud Service Mesh Outside Google Cloud
As I mentioned earlier, Cloud Service Mesh can be installed on your GKE clusters running outside of Google Cloud, on VMWare, in AWS and Azure, and even on bare metal. This is achieved by using Google’s asmcli tool to install an in-cluster control plane that is managed via Cloud Service Mesh. Your clusters must still belong to your GKE Enterprise fleet and will require connectivity to Google Cloud APIs.
The in-cluster service mesh supports either using Google’s Mesh CA service or the Istio CA service as a certificate authority. This is used when creating mutual TLS (mTLS) certificates, which I’ll explore in a future post. Mesh CA is a reliable and scalable managed service specifically designed for managing workload mTLS certificates, and it's recommended to use the Mesh CA for your service mesh. You can optionally choose to use an existing Istio CA if you already have one set up, if you require a custom CA, or if there’s another reason not to use Google’s CA service, but this is a complex outlier use case.
With this in mind, let’s look at the steps required to enroll a cluster that exists outside of Google Cloud. These instructions should work for any of the supported platforms I’ve talked about already.
Readying your cluster for service mesh
First, we’ll need to download Google’s asmcli tool. You should do this wherever you connect to your Kubernetes clusters (for example, your local computer). You can download the tool and make it executable with these commands:
curl https://storage.googleapis.com/csm-artifacts/asm/asmcli_1.20 > asmcli
chmod +x asmcli
Next, we need to create a cluster role binding so that we have the necessary permissions to create RBAC roles for service mesh. We’ll do this with the kubectl command, so it's important that you have authentication set up for your cluster in your local .kube/config file. How you achieve this will depend on where your cluster is running.
For each cluster context, run the following command to create the necessary permissions, swapping out you@youremail.com for the user account that you identify with when connecting to Kubernetes:
kubectl create clusterrolebinding cluster-admin-binding \
--clusterrole=cluster-admin \
--user=you@youremail.com
Now we can run the asmcli validate command. This will check that your project and cluster will support the service mesh’s minimum requirements, and that the necessary permissions and APIs are set up. This command will also download and extract some useful sample manifest files:
./asmcli validate \
--kubeconfig KUBECONFIG_FILE \
--fleet_id FLEET_PROJECT_ID \
--output_dir DIR_PATH \
--platform multicloud
To replace the placeholders:
KUBECONFIG_FILEshould point to your local.kube/configfile for authentication.FLEET_PROJECT_IDrefers to the project that owns your GKE fleet.DIR_PATHspecifies a local directory whereasmcliwill write installation files and sample manifests.
If asmcli detects any errors with your environment or clusters that might prevent service mesh from operating, it will report this to you and hopefully provided some suggested fixes. You will most likely see a few warnings that certain things need to be enabled (such as namespaces, cluster labels etc.), but we can actually get the asmcli command to do that for us in a moment.
Installing service mesh components
The next step is to install the service mesh control plane using the asmcli command. This process will register our clusters to the fleet (if they don’t already belong to it), install the service mesh components for the control and data planes, configure the mesh to trust the fleet’s workload identity, and finally set up remote secrets so that multiple clusters in the same fleet can trust each other.
Now that we’ve validated our environment, we can run the following command to install everything we need, substituting the same placeholders as last time:
./asmcli install \
--fleet_id FLEET_PROJECT_ID \
--kubeconfig KUBECONFIG_FILE \
--output_dir DIR_PATH \
--platform multicloud \
--enable_all \
--ca mesh_ca
Note the --enable_all option, which will correct any missing configuration that was identified during the validation stage. The --ca option specifies that we want to use Google’s managed Mesh CA service. When the command completes successfully, you will see a helpful note on how to enable sidecar injection.
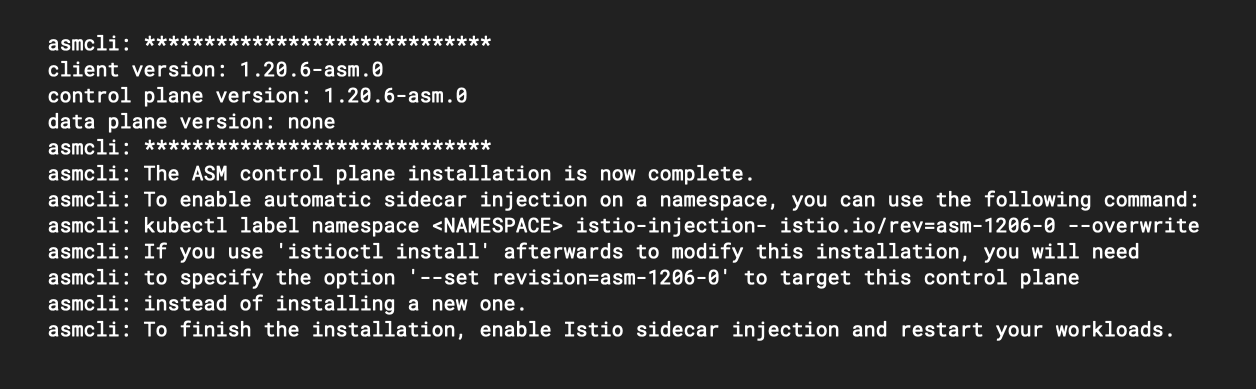
The service mesh should now be deployed and running! The last thing to do before we attempt any deployments is to enable the sidecar auto-injection. You should be able to use the command that you captured previously from the output of the asmcli installation. If you don’t have this command to hand, all you need to do is find out the revision label for the isiotd deployment. We can find this out with this command:
kubectl -n istio-system get pods -l app=istiod --show-labels
Just look for the istio.io/rev label in the output. You should see something like istio.io/rev=asm-1206-0. You can then use this label to apply to a namespace like this:
kubectl label namespace my-namespace istio.io/rev=asm-1206-0 --overwrite
At the time of writing there was one final quirk that you may need to deal with: application monitoring and logging are not enabled by default for clusters outside of Google Cloud. We definitely want to see all the helpful visualisations in the Cloud Service Mesh dashboard, so we need to take steps to switch this functionality on.
An object called stackdriver in the kube-system namespace manages the integration of application logging. We can edit this object in situ and set the value of enableCloudLoggingForApplications to true. This can be done with the kubectl edit command:
kubectl –n kube-system edit stackdriver stackdriver
Look for the enableCloudLoggingForApplications option in the spec and set it to true. Hopefully this option will be automated in future releases!
Meshing multiple clusters externally
Now we understand how to deploy Cloud Service Mesh to clusters outside of Google Cloud, we can start to build up an external multi-cluster mesh. This solution is technically supported by Google provided that all clusters exist within the same single environment, whether that is in GKE on VMware, bare metal, Azure or AWS.
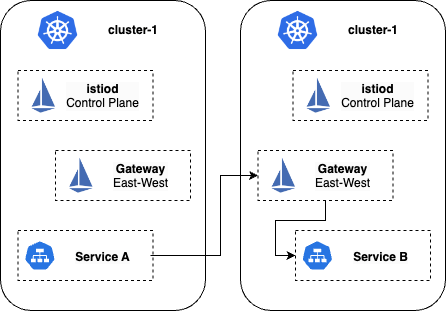
At a high level, we can mesh multiple clusters together by following these steps:
Creating an east-west gateway between the clusters
Exposing local services through the gateways
Enabling endpoint discovery
Google’s guide on how to set up this external multi-cluster mesh has a few different dependencies. Be careful, because you’re now at the cutting edge of multi-cluster technology, where things break easily!
Assuming we have two clusters in one of the supported environments, and that we’ve already installed Cloud Service Mesh, let’s walk through how to action these steps and get our clusters talking to each other. We’ll need a handful of files from the Anthos Service Mesh packages git repo we obtained earlier (available from https://github.com/GoogleCloudPlatform/anthos-service-mesh-packages/tree/).
You will also need the istioctl tool installed, which you can obtain from https://istio.io/latest/docs/setup/getting-started/
Inside the git repo, navigate to the asm/istio/expansion folder, where you’ll find a shell script called gen-eastwest-gateway.sh. This script takes in options about your environment and dynamically generates an IstioOperator object, which is then piped via the istioctl command into your cluster.
Assuming the kubectl context for your first cluster is called cluster-1, run the following command for GKE on VMware or GDVC Bare Metal clusters:
gen-eastwest-gateway.sh \
--revision asm-1213-3 | istioctl --context cluster-1 \
install -y --set spec.values.global.pilotCertProvider=kubernetes -f -
Or this version of the command if the clusters are running in Azure or AWS:
gen-eastwest-gateway.sh \
--revision asm-1213-3 | istioctl --context cluster-1 \
install -y --set spec.values.global.pilotCertProvider= istiod -f -
Repeat the instructions for your other cluster, using the appropriate kubectl context.
Next, we’ll create the Gateway object that exposes services across both clusters. In the same git repo directory, you’ll find a script called expose-services.yaml. Run this for each of your cluster contexts, for example:
kubectl --context cluster-1 apply -n istio-system -f expose-services.yaml
Finally, we enable endpoint discovery by asking the asmcli tool to create the mesh. Sadly, at the time of writing, the tooling is still quite immature. Outside of Google Cloud, asmcli doesn’t have an easy way to identify clusters. To create the mesh, you must pass in individual kubeconfig files that contain the authentication credentials for each individual cluster. It’s likely that these credentials are all in one big .kube/config file right now, but you’ll need to manually split them out into individual files. Then you can run the command like this:
./asmcli create-mesh FLEET_PROJECT_ID \
KUBECONFIG_FILE_1 KUBECONFIG_FILE_2
Replace FLEET_PROJECT_ID with the Google Cloud project ID that hosts your GKE fleet and substitute the other parameters with the filenames of the individual cluster credentials files you just created, and finally, you should have a multi-cluster mesh set up and ready to go! Feel free to return to the Hello World example from earlier in this post and test it out on your new non-Google fleet. Services should now be able to communicate across clusters via the gateways you configured.
Configuring a true hybrid mesh
A true hybrid mesh would involve creating a single service mesh, including full service discovery, across multiple clusters that exist in different environments. At the time of writing, this capability was in preview for clusters that span GKE on Google Cloud and GKE on VMWare or bare metal. If you want to give this a try, see the documentation at https://cloud.google.com/service-mesh/docs/operate-and-maintain/hybrid-mesh. Needless to say, unless the offering and tooling has evolved considerably by the time you read this, the solution is not recommended for production environments!
Summary
We are now two-thirds of the way through our exploration of Cloud Service Mesh and service mesh principles in general. This post may have you thinking that the technologies involved are simply too immature and unstable to risk in production, despite the extra functionality that a service mesh provides. This is often the side effect of a cloud provider like Google Cloud taking a dynamic open-source project (in this case: Istio) and attempting to turn it into a managed service. The technology doesn’t slow down, and while we are usually willing to do some work “under the hood” on our own projects, we usually have high expectations of fully managed services. It’s likely that Google will continue to refine the offering of Cloud Service Mesh so that one day soon the experience in all environments, or across hybrid deployments, is just as smooth as when you mesh clusters inside Google Cloud.
In the meantime, Cloud Service Mesh inside Google Cloud can be considered quite stable, and running the service on a single external cluster is well supported by the existing tooling. While Google continues to improve its tools, you could consider managing your own Istio deployments for hybrid or multi-cluster scenarios – after all, outside of Google’s customer base, this is how lots of other people are managing meshed container workloads.
In my next planned post I’ll finish our Service Mesh journey by discussing its potential for securing our workloads. Thankfully, this is an area where the technology is mature and works well across any environment once you’ve done the hard work of installing the mesh!