Building GKE Clusters in Google Cloud and AWS

This is the second post in a series exploring the features of GKE Enterprise, formerly known as Anthos. GKE Enterprise is an additional subscription service for GKE that adds configuration and policy management, service mesh and other features to support running Kubernetes workloads in Google Cloud, on other clouds and even on-premises. If you missed the first post, you might want to start there.
In this post, I'll begin to introduce the fundamental components of GKE Enterprise and highlight what makes it different from running a standard GKE cluster. To ease us into the hybrid world of GKE Enterprise, we’ll start just by focusing on cloud-based deployments in this post and explore VMWare and bare metal options next time around. This should give us a solid foundation to work from before we explore any further complex topics.
The primary benefit of using GKE Enterprise is the ability it gives you to run Kubernetes clusters in any cloud while maintaining a single developer experience and a centralised approach to management. You may have an organisational need to deploy to multiple clouds, perhaps for additional redundancy and availability purposes, or maybe just so you’re not putting all your eggs in a single vendor’s basket. GKE Enterprise allows you to deploy to Google Cloud, AWS and even Azure with a simplified workflow, so you have complete freedom to choose the target for your workload deployments.
If you want to follow along with anything in this post, you'll need a Google Cloud account (and an AWS account if you follow that part as well). Google used to offer an introductory cloud credit of $300, but that seems to have been changed into an unfathomable number of Gemini token credits, which aren't so useful for building infrastructure. Still, there are free usage quotas for most products. Meanwhile, AWS has a free tier that's equally difficult to decipher. In any case, if you are trying to learn this stuff to help with your job, by all means ask your employer to pay for it. Things can get expensive quickly!
I'm going to repeat this one more time: 😬 Using any cloud vendor means you are liable to be charged for services – that's how they make their money after all. Even with free trials and special offers, you should expect to pay something, and that something can quickly turn into a big something if you forget to delete resources. Please be careful!
With that disclaimer out of the way, let's dive back into GKE Enterprise.
GKE Enterprise Components
Fundamentally, GKE Enterprise is a system for running Kubernetes anywhere but managing it from a single place. Many different components are combined to achieve this which operate at different layers, from infrastructure to the network layer to service and policy management. At the lowest level, Kubernetes clusters are used to manage the deployment of workloads, and these can take several forms. In Google Cloud, you obviously deploy GKE clusters. When you use GKE Enterprise to deploy to environments outside of Google Cloud, the service will create GKE-managed clusters which it will operate for you (these were formally referred to as "GKE On-Prem clusters" even if they ran in other clouds). Finally, you can even choose to bring the management of an existing vanilla Kubernetes cluster into GKE Enterprise.
At the network layer, GKE Enterprise will leverage various connectivity options to communicate with your other environments. You may choose to set up VPN connections for example, or configure a dedicated Interconnect if you expect high traffic between your Google Cloud projects and other locations. GKE Enterprise communicates with clusters in other environments using a component called the Connect Gateway. This gateway provides a communication bridge between a remote cluster’s API and the control plane of your GKE Enterprise environment. Using the gateway allows GKE Enterprise to issue commands and control additional clusters on other clouds or on-premises. We’ll see how this is used to set up clusters in AWS later in this post. Above this layer are tools to control our workloads, such as service mesh, configuration management, and policy control, which we’ll discuss much later on in this series.
As you can imagine, when operating and managing multiple clusters, you will need some additional help to organise all of your resources, which is why GKE Enterprise uses a concept called fleets. A fleet is simply a logical grouping of Kubernetes clusters, allowing you to manage all clusters in that fleet rather than dealing with them individually. A single fleet can contain clusters that all run within Google Cloud or a combination of clusters running across a variety of environments. Fleets offer many different design patterns for workload, environment, and tenant isolation and also provide other powerful features beyond simple logical cluster groupings. I'll cover these options in more detail later in the series, but for now, you just need to know that all clusters in GKE Enterprise must belong to a fleet.
Building your first Enterprise cluster
With enough of the basic concepts covered, it’s now time to create your first GKE Enterprise cluster. To do this, we’ll first enable GKE Enterprise and set up a fleet associated with our project. Then we’ll create a GKE cluster and register it to that fleet. This post is about deploying GKE in the cloud – not just in Google Cloud, so once our fleet is running, we’ll set up a similar cluster in AWS and observe how GKE’s fleet management allows us to centrally manage both clusters.
Enabling GKE Enterprise
As I mentioned in the first post, GKE Enterprise is an add-on subscription service. To enable it, you will need a Google Cloud project with a valid billing account, and while it does come with its own free trial, the switch from GKE Standard to GKE Enterprise is likely to take you out of any free tier or free credits you may have. Once GKE Enterprise is enabled, all registered GKE Enterprise clusters will incur per-vCPU charges. Please read the pricing guide for more information at: https://cloud.google.com/kubernetes-engine/pricing.
Have I scared you off yet? 😂 If you're still here, let's do this!
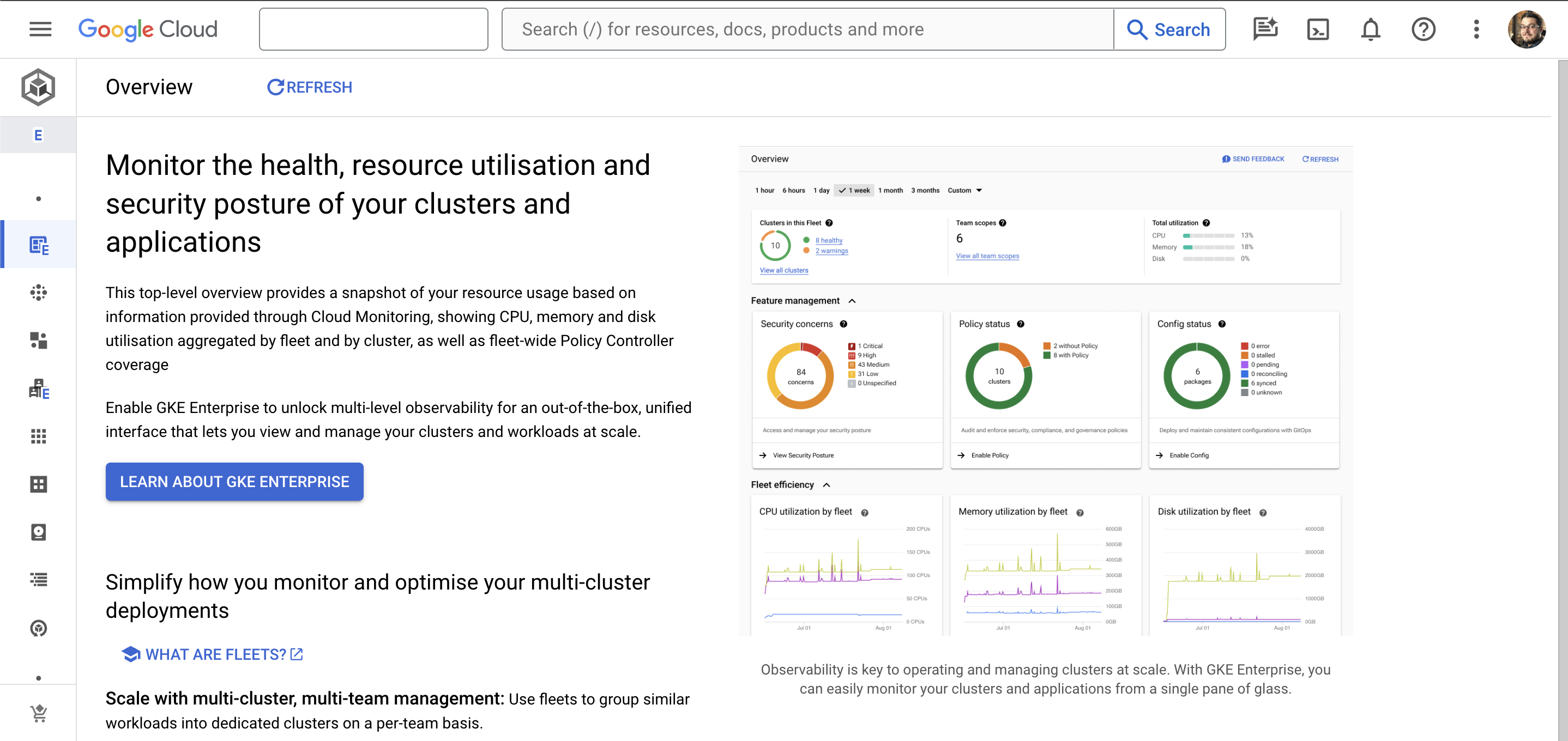
From the Google Cloud console page, select Kubernetes Engine in the navigation menu.
In the Overview section of Kubernetes Engine, you will see a button that says Learn About GKE Enterprise. Click this button.
A pop-over box will appear containing details of the benefits of GKE Enterprise. At the bottom of this box is a button labeled Enable GKE Enterprise. You can optionally tick the 90-day free trial option (if it is still on offer when you’re reading this) which should waive the per-vCPU charges for 90 days.
Click the Enable GKE Enterprise button. A confirmation pop-over will appear next. This shows you the APIs that will be enabled for your project and it will also tell you the name of the default fleet that will be created for GKE Enterprise. You can edit, create, and delete this and other fleets later.
Click Confirm to proceed with enabling GKE Enterprise.
After a few moments, you will see a confirmation message. It will also prompt you to create your first cluster, but we’ll do that separately in a moment. You can now close this pop-over box and return to the Kubernetes Engine section. You should see that you’re back on the overview page with a dashboard showing you the current state of your fleet.
Creating the cluster
Creating a cluster inside a GKE Enterprise fleet is very similar to how you create a GKE Standard edition cluster, although you’ll see a few extra options are now available to you.
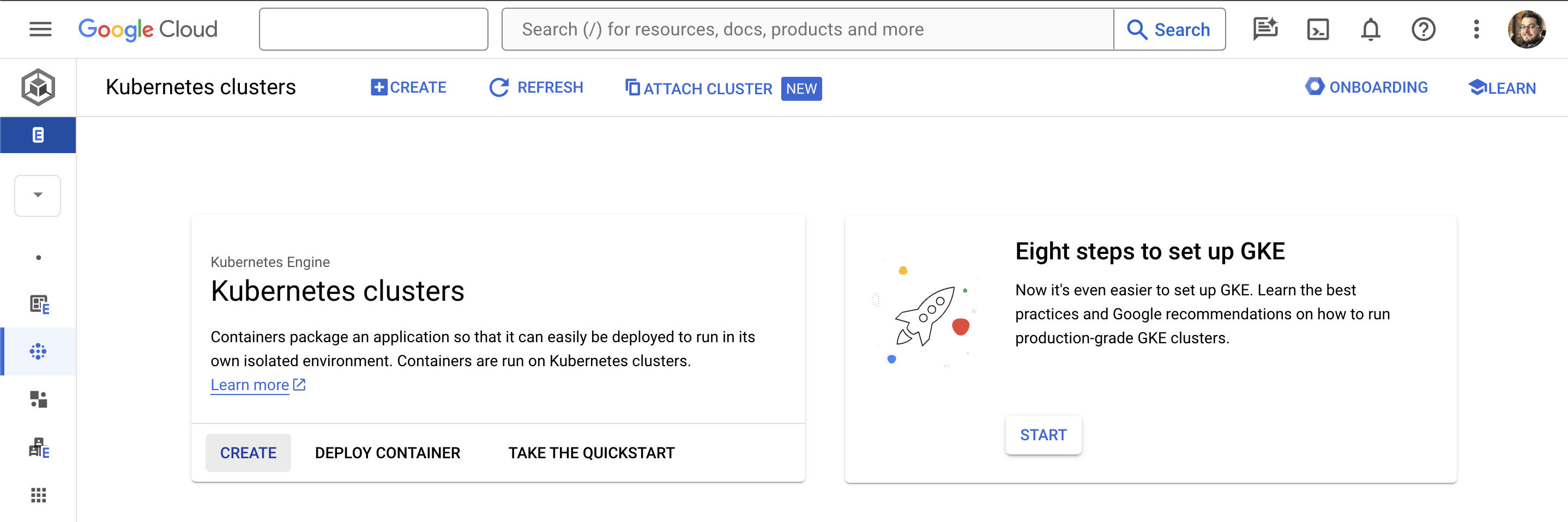
From the Kubernetes Engine section, select Clusters in the left-hand menu.
Click the Create button at the top of the page. The cluster configuration dialog box that pops up contains options for creating standard or autopilot clusters on Google Cloud, as well as GKE clusters on other clouds and even on-premises. At the time of writing, not all of these were supported as options in the UI and some required using the command line instead. For now, we’ll stick with the recommended Autopilot cluster type on Google Cloud. Click Configure on this option.
We could click Create at this stage and accept all of the defaults, but let’s walk through the setup so we understand what we’re creating: On the first page, Cluster basics, give your cluster a name of your choice and choose a region. This could be a region closest to you, or if you prefer you can use the default region which may be cheaper. Then click Next: Fleet Registration.
On the next page, you can choose to register your cluster to your fleet. As you can see, there’s an option to skip this, but the whole point of GKE Enterprise is to manage clusters across different environments, so go ahead and check the box. You’ll see a pop-up notifying you that no additional fleet features have been configured so far, but we’ll come back to those in a later post. Now you can click Next: Networking.
Just like a GKE Standard cluster, we have several networking options that you are probably already familiar with, such as which network and subnet your GKE nodes should run in, and whether the cluster should run with public or private IP addresses. Let’s leave this at the defaults for now and click Next: Advanced Settings.
In the Advanced Settings section, we can choose the release channel, which again is the same principle we would use for a GKE Standard cluster. Let’s stick to the regular channel for now. Notice all the drop-down boxes for the different advanced features. Have a look through and see what GKE Enterprise can offer you, but for now, don’t select anything other than the defaults. We’ll explore a lot of these options later in the blog. Now click Next: Review and Create.
Finally, review the options you’ve chosen for your cluster, and click Create Cluster.
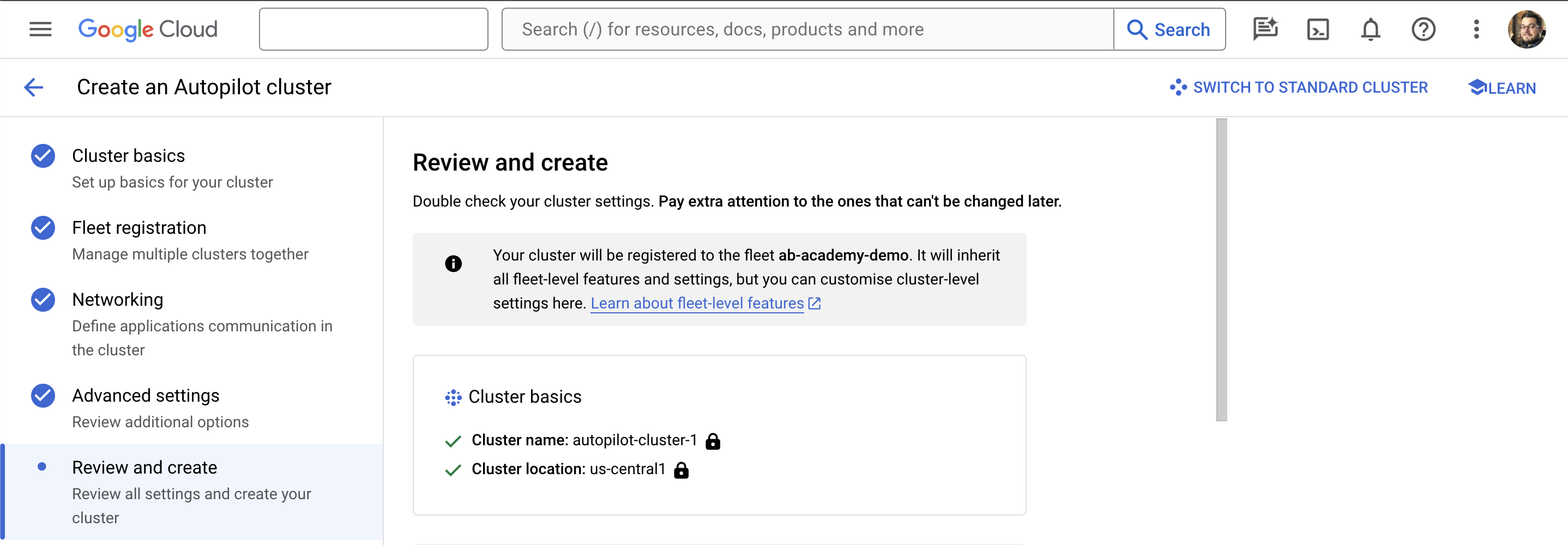
After 5-10 minutes, your GKE Autopilot cluster will be built, ready to use, and registered to your GKE Enterprise fleet.
Testing a Deployment
Now we'll use the built-in deployment tool in the cloud console to test a deployment to our new cluster. Of course, you’re welcome to use any other deployment method you may be familiar with (for example, command-line kubectl), because this is just a regular Kubernetes cluster behind the scenes, even if Google manages the nodes for us in autopilot mode.
From the Kubernetes Engine section, select Workloads in the left-hand menu.
Click the Deploy button at the top of the page. Enter the following container image path as a single line:
us-docker.pkg.dev/google-samples/containers/gke/hello-app:1.0Click Continue then change the deployment name to
hello-world. Then click Continue again (don’t deploy it just yet!)In the optional Expose section, check the box to also create a matching service for the deployment. In the Port Mapping section that appears, make sure you change the
Item 1: Port 1port number to8080– this is the port the container listens on. Accept the defaults and click Deploy.
After a few minutes, your deployment should be up and running and your service should be exposed. If you see errors at first (about Pods not being able to be scheduled, or the deployment not meeting minimum availability), just wait a few more minutes and refresh the page. Autopilot is scaling up the necessary infrastructure for your workload behind the scenes.
When your workload shows a green tick, you can click the link at the bottom of the page under Endpoints to view your new application. In a moment, we’ll repeat these steps for a completely different cloud just to see how easy it is to perform multi-cloud deployments from GKE Enterprise.
Automating with Terraform
Just like everything else in Google Cloud, we can automate the creation of GKE Enterprise components (and Kubernetes components) too. Let's walk through a basic example of using Terraform to automate everything we’ve just built so far. I don't want to go off on a tangent into how to learn Terraform from scratch, so to follow along below I'll assume that you already have the Terraform command line tools set up and ready to go for your Google Cloud project. You’ll need a service account with the necessary project permissions and a JSON key file which we’ll refer to as serviceaccount.json.
You can also find the code below in my Github repo here: https://github.com/timhberry/gke-enterprise/tree/main/gke-cluster-tf
First, we’ll create a file called terraform.tfvars. This file will store the name of our project ID and the default Google Cloud region we want to use. Make sure you update these values to match your own project and preferred region:
project_id = "my-googlecloud-project"
region = "us-east1"
Next, we’ll create a new VPC and subnetwork to use for our cluster. In the example we went through a moment ago we used the default VPC network that is configured by default in all Google Cloud projects. However, when using infrastructure as code, it is better to create and manage all resources rather than to rely on the assumption that they exist and are accessible.
Create the following vpc.tf file:
variable "project_id" {
description = "project id"
}
variable "region" {
description = "region"
}
provider "google" {
credentials = file("serviceaccount.json")
project = var.project_id
region = var.region
}
resource "google_compute_network" "gke-vpc" {
name = "gke-vpc"
auto_create_subnetworks = "false"
}
resource "google_compute_subnetwork" "gke-subnet" {
name = "gke-subnet"
region = var.region
network = google_compute_network.gke-vpc.name
ip_cidr_range = "10.10.0.0/24"
}
Let's walk through this code.
First, we create two variables that we can use later:
project_idandregion. This allows us to read the variables from theterraform.tfvarsfile that we created first. This makes our code somewhat portable and reusable, so it's a good practice to follow.Next, we set up the Google provider. Here we pass in the
serviceaccount.jsoncredentials file that we mentioned earlier and configure our project ID and default region.Finally, we create two new resources, a
google_compute_network(ie., a VPC), and agoogle_compute_subnetworkinside it. As you can see, we switch off the automatic creation of subnetworks, so this VPC will only contain the one subnetwork that we have chosen to create. This subnetwork gets set up in the region we chose, with an IP address range of10.10.0.0/24.
Now we’ll define the cluster itself. Create the following cluster.tf file:
resource "google_gke_hub_fleet" "dev-fleet" {
display_name = "My Dev Fleet"
}
resource "google_container_cluster" "gcp-cluster" {
name = "gcp-cluster"
location = var.region
enable_autopilot = true
network = google_compute_network.gke-vpc.name
subnetwork = google_compute_subnetwork.gke-subnet.name
}
resource "google_gke_hub_membership" "membership" {
membership_id = "basic"
location = var.region
endpoint {
gke_cluster {
resource_link = "//container.googleapis.com/${google_container_cluster.gcp-cluster.id}"
}
}
}
data "google_client_config" "provider" {}
data "google_container_cluster" "gcp-cluster" {
name = "gcp-cluster"
location = var.region
}
provider "kubernetes" {
host = "https://${data.google_container_cluster.gcp-cluster.endpoint}"
token = data.google_client_config.provider.access_token
cluster_ca_certificate = base64decode(
data.google_container_cluster.gcp-cluster.master_auth[0].cluster_ca_certificate,
)
}
There’s quite a lot to unpack here, so let’s go through the code block by block.
The first resource we create is a
google_gke_hub_fleet, which we calldev-fleet. This is our GKE Enterprise fleet, which as we’ve discussed can manage multiple clusters for us.Next, we create the
google_container_cluster. We give the cluster a name, specify its location and network settings, and make sure we turn on Autopilot mode. There are of course all kinds of other options we could specify here for the configuration of our cluster, but to keep it simple we’re just specifying the required settings, and we’ll accept the defaults for everything else.Now we have a cluster, we can join it to the fleet. We do this with a
google_gke_hub_membershipresource. This simply joins the cluster we just created by using Terraform’s own resource link.Finally, we want to be able to use Terraform to actually configure some Kubernetes objects, not just the cluster and fleet themselves. So we need to configure a Kubernetes provider. We do this by configuring our new cluster as a data source and then referencing it to extract the cluster certificate in the configuration of our Kubernetes provider. Doing this means that Terraform can send authenticated requests directly to the Kubernetes API to create and manage objects for us.
At this point, we have declared our fleet and our cluster, and we’ve configured the Kubernetes provider. Now we can move away from infrastructure and onto our workloads themselves.
The last file we’ll create is a deployment.tf that contains our Kubernetes deployment and service:
resource "kubernetes_deployment" "hello-world" {
metadata {
name = "hello-world"
labels = {
app = "hello-world"
}
}
spec {
selector {
match_labels = {
app = "hello-world"
}
}
template {
metadata {
labels = {
app = "hello-world"
}
}
spec {
container {
image = "us-docker.pkg.dev/google-samples/containers/gke/hello-app:1.0"
name = "hello-world"
}
}
}
}
}
resource "kubernetes_service" "hello-world" {
metadata {
name = "hello-world"
}
spec {
selector = {
app = kubernetes_deployment.hello-world.spec.0.template.0.metadata.0.labels.app
}
port {
port = 80
target_port = 8080
}
type = "LoadBalancer"
}
}
You should already be familiar with these basic Kubernetes building blocks, so we don’t need to examine this code too carefully. As you can probably tell, the configuration is very similar to what we would write if we were just sending a YAML file directly into kubectl. In Terraform of course, we use Hashicorp’s configuration language (HCL) which looks a little bit like JSON, just more verbose. All the usual things are there for a deployment and a service, including the container image name and target port. You can see in the service where we link the selector to the Terraform resource for the deployment.
If your Terraform environment is configured correctly and your service account has the correct permissions, you should now be able to spin up these resources by following the normal Terraform workload of init, plan, and apply. If you have any issues with your code, you can check it against the GitHub repo I mentioned earlier.
One final note on fleets – although again, we’ll be exploring these in much more detail later in the series. If you already created a fleet by hand following the steps earlier in this post, and then you tried to create a new fleet in the same project using Terraform, you may have seen an error. That’s because a single project can only contain a single fleet. If you still want to proceed, you can simply remove the google_gke_hub_fleet resource from the Terraform code, so it doesn’t try to create a new fleet. Leave in the google_gke_hub_membership resource for your cluster, and it will join the existing fleet in the project.
Setting up our first cluster inside Google Cloud probably seemed quite easy, and that’s because it is most definitely designed that way. Next, we’ll look at how we can set up GKE Enterprise to build a cluster in AWS, which will involve laying down a few more foundations first. As you read through these sections you may find that the steps involved are quite long and complicated, but bear in mind that much of the groundwork only needs to be done once, and of course, it too can be automated by tools like Terraform.
Building clusters on AWS
Getting GKE Enterprise ready to deploy into AWS for you requires many different moving parts. At a high level, we need to perform the following steps:
Create an AWS VPC with the correct subnets, routes and gateways.
Configure keys for the encryption of EC2 instance data, EBS volumes in AWS and ETCD state data in our clusters.
Create IAM roles and SSH key pairs GKE runs within its own VPC inside your AWS account, which will include private and public subnets.
The private subnets will host the EC2 virtual machines that provide control plane nodes as well as worker nodes (organised into node pools) for your cluster. An internal network load balancer will provide the front end for the control plane. Finally, NAT gateways will operate in the public subnets to provide connectivity for the private subnets.
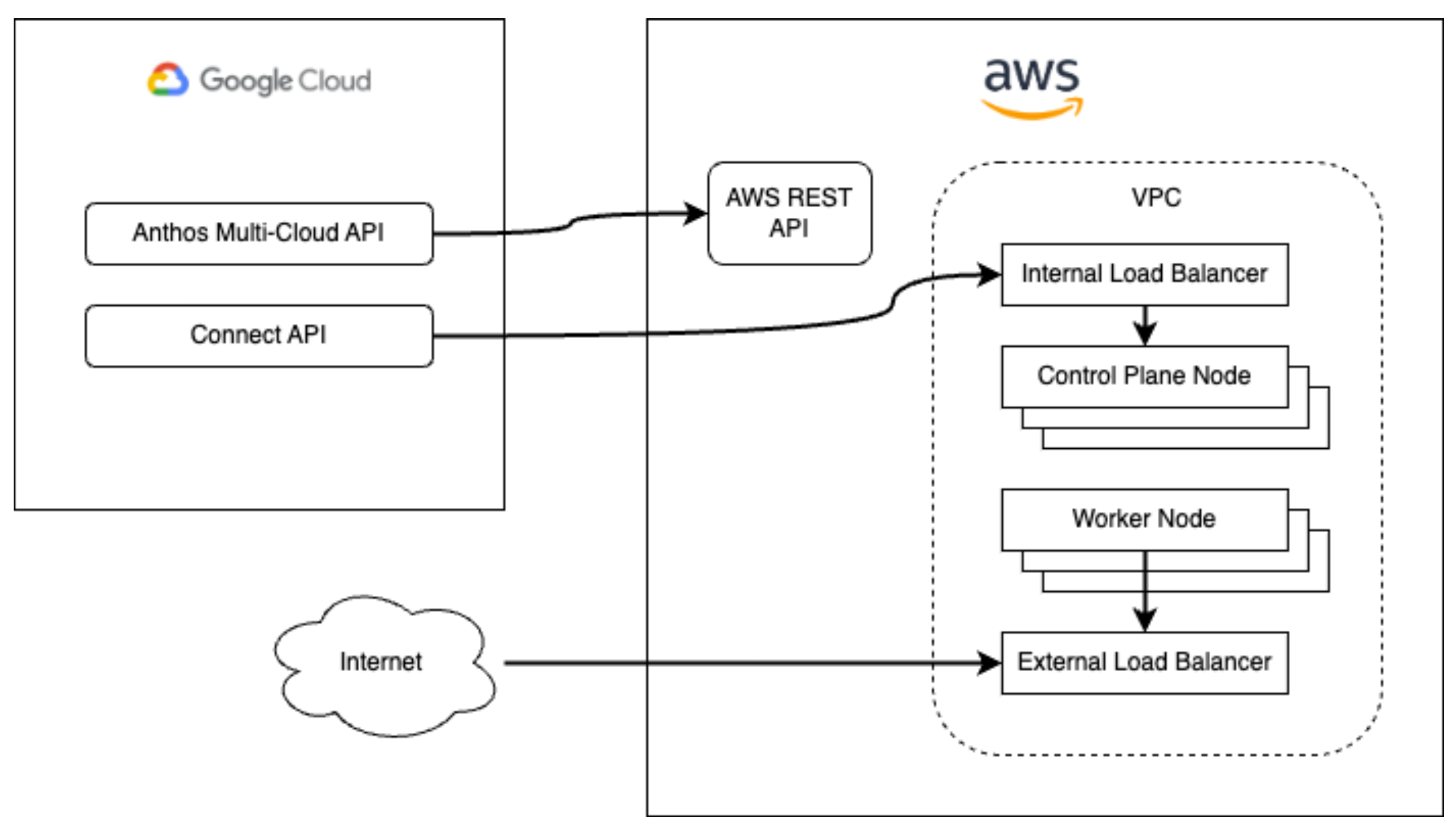
The Anthos Multi-Cloud API (as it was still named at the time of writing) communicates with the AWS API to manage AWS resources, while the Connect API communicates with the Kubernetes API of the cluster running in AWS. This allows you to create and manage your AWS clusters entirely from within the Google Cloud console, provided the foundations have been configured first.
There is a lot of groundwork to cover in setting up AWS for GKE. Many complex commands are required over hundreds and hundreds of lines. You definitely want to automate this! I'll walk through everything below, but I've also provided the commands in a set of scripts in my GitHub repo here: https://github.com/timhberry/gke-enterprise/tree/main/aws-cluster-scripts
For reference, the scripts are:
aws-keys.sh- Creating KMS and SSH key pairsaws-iam.sh- Creating the necessary IAM roles, policies and profilesaws-vpc.sh- Creating the VPC network, subnets, routes and gatewaysaws-cluster.sh- Finally creating the cluster and node pool
The commands in these scripts rely on you having the gcloud and aws command-line tools installed and configured, and you'll also need the jq JSON tool. Finally, I've only tested these commands on Linux and MacOS. If you are using Windows, it’s recommended to use the Windows Subsystem for Linux to provide a proper Linux shell experience. Alternatively, you can use the Cloud Shell terminal in the Google Cloud console. Also, note that the scripts use the us-east-1 region, but you can change that if you prefer. I also have a convention of prefixing names with gke-cluster which you can also change if you like.
Oh, and don't just run the scripts as-is! They're supposed to helpfully compile the commands together, but you should definitely run each command one at a time to help you spot any errors. Some commands create environment variables that are used in later commands. So much preamble!
Encryption keys first
GKE Enterprise uses the AWS Key Management Service (KMS) to create symmetric encryption keys. These are then used for encryption of Kubernetes state data in etcd, EC2 instance user data, and at-rest encryption of data on EBS volumes including control plane and node pool data.
In a production environment, you should use different keys for different components, for example by encrypting configuration and volumes separately. It’s also recommended to further secure the key policy by using a minimum set of KMS permissions. However, this is not an AWS Security post, so for now, we’ll be creating a single KMS key for our purposes.
Side note: everything you create in AWS gets a unique resource name, or ARN, and often we need to reference the ARNs of resources we've already created. When we need to do this, we'll pipe the output to jq and store the result in an environment variable.
KMS_KEY_ARN=$(aws --region us-east-1 kms create-key \
--description "gke-key" \
--output json| jq -r '.KeyMetadata.Arn')
Next, we'll create an EC2 SSH key pair for our EC2 instances, just in case we ever need to connect to them for troubleshooting purposes:
ssh-keygen -t rsa -m PEM -b 4096 -C "GKE key pair" \
-f gke-key -N "" 1>/dev/null
aws ec2 import-key-pair --key-name gke-key \
--public-key-material fileb://gke-key.pub
IAM permissions
Several sets of IAM permissions will need to be set up in your AWS account for GKE Enterprise to work. First, let's set some environment variables that reference the Google Cloud project where our fleet exists:
PROJECT_ID="$(gcloud config get-value project)"
PROJECT_NUMBER=$(gcloud projects describe "$PROJECT_ID" \
--format "value(projectNumber)")
We'll now create an AWS IAM role for the GKE Multi-Cloud API. Remember, this is the API that will communicate directly with the AWS API when we ask GKE to run commands or control components within AWS:
aws iam create-role --role-name gke-api-role \
--assume-role-policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Federated": "accounts.google.com"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"accounts.google.com:sub": "service-'$PROJECT_NUMBER'@gcp-sa-gkemulticloud.iam.gserviceaccount.com"
}
}
}
]
}'
Almost forgot! We actually need the ARN for this role, so let's grab it:
API_ROLE_ARN=$(aws iam list-roles \
--query 'Roles[?RoleName==`gke-api-role`].Arn' \
--output text)
Now, the GKE IAM role will needs lots of different permissions, so we'll create a new AWS IAM policy for this:
API_POLICY_ARN=$(aws iam create-policy --policy-name gke-api-policy \
--policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Action": [
"ec2:AuthorizeSecurityGroupEgress",
"ec2:AuthorizeSecurityGroupIngress",
"ec2:CreateLaunchTemplate",
"ec2:CreateNetworkInterface",
"ec2:CreateSecurityGroup",
"ec2:CreateTags",
"ec2:CreateVolume",
"ec2:DeleteLaunchTemplate",
"ec2:DeleteNetworkInterface",
"ec2:DeleteSecurityGroup",
"ec2:DeleteTags",
"ec2:DeleteVolume",
"ec2:DescribeAccountAttributes",
"ec2:DescribeInstances",
"ec2:DescribeInternetGateways",
"ec2:DescribeKeyPairs",
"ec2:DescribeLaunchTemplates",
"ec2:DescribeNetworkInterfaces",
"ec2:DescribeSecurityGroupRules",
"ec2:DescribeSecurityGroups",
"ec2:DescribeSubnets",
"ec2:DescribeVpcs",
"ec2:GetConsoleOutput",
"ec2:ModifyInstanceAttribute",
"ec2:ModifyNetworkInterfaceAttribute",
"ec2:RevokeSecurityGroupEgress",
"ec2:RevokeSecurityGroupIngress",
"ec2:RunInstances",
"iam:AWSServiceName",
"iam:CreateServiceLinkedRole",
"iam:GetInstanceProfile",
"iam:PassRole",
"autoscaling:CreateAutoScalingGroup",
"autoscaling:CreateOrUpdateTags",
"autoscaling:DeleteAutoScalingGroup",
"autoscaling:DeleteTags",
"autoscaling:DescribeAutoScalingGroups",
"autoscaling:DisableMetricsCollection",
"autoscaling:EnableMetricsCollection",
"autoscaling:TerminateInstanceInAutoScalingGroup",
"autoscaling:UpdateAutoScalingGroup",
"elasticloadbalancing:AddTags",
"elasticloadbalancing:CreateListener",
"elasticloadbalancing:CreateLoadBalancer",
"elasticloadbalancing:CreateTargetGroup",
"elasticloadbalancing:DeleteListener",
"elasticloadbalancing:DeleteLoadBalancer",
"elasticloadbalancing:DeleteTargetGroup",
"elasticloadbalancing:DescribeListeners",
"elasticloadbalancing:DescribeLoadBalancers",
"elasticloadbalancing:DescribeTargetGroups",
"elasticloadbalancing:DescribeTargetHealth",
"elasticloadbalancing:ModifyTargetGroupAttributes",
"elasticloadbalancing:RemoveTags",
"kms:DescribeKey",
"kms:Encrypt",
"kms:GenerateDataKeyWithoutPlaintext"
],
"Resource": "*"
}
]
}' --output json | jq -r ".Policy.Arn")
Now we'll attach the policy to the role:
aws iam attach-role-policy \
--policy-arn $API_POLICY_ARN \
--role-name gke-api-role
Next, we create another IAM role, this time for the nodes that will make up our control plan:
aws iam create-role --role-name control-plane-role \
--assume-role-policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Service": "ec2.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}'
We'll also need to create a new policy for this role:
CONTROL_PLANE_POLICY_ARN=$(aws iam create-policy --policy-name control-plane-policy \
--policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Action": [
"ec2:AttachNetworkInterface",
"ec2:AttachVolume",
"ec2:AuthorizeSecurityGroupIngress",
"ec2:CreateRoute",
"ec2:CreateSecurityGroup",
"ec2:CreateSnapshot",
"ec2:CreateTags",
"ec2:CreateVolume",
"ec2:DeleteRoute",
"ec2:DeleteSecurityGroup",
"ec2:DeleteSnapshot",
"ec2:DeleteTags",
"ec2:DeleteVolume",
"ec2:DescribeAccountAttributes",
"ec2:DescribeAvailabilityZones",
"ec2:DescribeDhcpOptions",
"ec2:DescribeInstances",
"ec2:DescribeInstanceTypes",
"ec2:DescribeInternetGateways",
"ec2:DescribeLaunchTemplateVersions",
"ec2:DescribeRegions",
"ec2:DescribeRouteTables",
"ec2:DescribeSecurityGroups",
"ec2:DescribeSnapshots",
"ec2:DescribeSubnets",
"ec2:DescribeTags",
"ec2:DescribeVolumes",
"ec2:DescribeVolumesModifications",
"ec2:DescribeVpcs",
"ec2:DetachVolume",
"ec2:ModifyInstanceAttribute",
"ec2:ModifyVolume",
"ec2:RevokeSecurityGroupIngress",
"autoscaling:DescribeAutoScalingGroups",
"autoscaling:DescribeAutoScalingInstances",
"autoscaling:DescribeLaunchConfigurations",
"autoscaling:DescribeTags",
"autoscaling:SetDesiredCapacity",
"autoscaling:TerminateInstanceInAutoScalingGroup",
"elasticloadbalancing:AddTags",
"elasticloadbalancing:ApplySecurityGroupsToLoadBalancer",
"elasticloadbalancing:AttachLoadBalancerToSubnets",
"elasticloadbalancing:ConfigureHealthCheck",
"elasticloadbalancing:CreateListener",
"elasticloadbalancing:CreateLoadBalancer",
"elasticloadbalancing:CreateLoadBalancerListeners",
"elasticloadbalancing:CreateLoadBalancerPolicy",
"elasticloadbalancing:CreateTargetGroup",
"elasticloadbalancing:DeleteListener",
"elasticloadbalancing:DeleteLoadBalancer",
"elasticloadbalancing:DeleteLoadBalancerListeners",
"elasticloadbalancing:DeleteTargetGroup",
"elasticloadbalancing:DeregisterInstancesFromLoadBalancer",
"elasticloadbalancing:DeregisterTargets",
"elasticloadbalancing:DescribeListeners",
"elasticloadbalancing:DescribeLoadBalancerAttributes",
"elasticloadbalancing:DescribeLoadBalancerPolicies",
"elasticloadbalancing:DescribeLoadBalancers",
"elasticloadbalancing:DescribeTargetGroups",
"elasticloadbalancing:DescribeTargetHealth",
"elasticloadbalancing:DetachLoadBalancerFromSubnets",
"elasticloadbalancing:ModifyListener",
"elasticloadbalancing:ModifyLoadBalancerAttributes",
"elasticloadbalancing:ModifyTargetGroup",
"elasticloadbalancing:RegisterInstancesWithLoadBalancer",
"elasticloadbalancing:RegisterTargets",
"elasticloadbalancing:SetLoadBalancerPoliciesForBackendServer",
"elasticloadbalancing:SetLoadBalancerPoliciesOfListener",
"elasticfilesystem:CreateAccessPoint",
"elasticfilesystem:DeleteAccessPoint",
"elasticfilesystem:DescribeAccessPoints",
"elasticfilesystem:DescribeFileSystems",
"elasticfilesystem:DescribeMountTargets",
"kms:CreateGrant",
"kms:Decrypt",
"kms:Encrypt",
"kms:GrantIsForAWSResource"
],
"Resource": "*"
}
]
}' --output json | jq -r ".Policy.Arn")
And then attach that policy to the role:
aws iam attach-role-policy \
--policy-arn $CONTROL_PLANE_POLICY_ARN \
--role-name control-plane-role
Now, because we're using this role and policy with EC2 instances, we'll also create an instance profile, and add the role to it:
CONTROL_PLANE_PROFILE=control-plane-profile
aws iam create-instance-profile \
--instance-profile-name $CONTROL_PLANE_PROFILE
aws iam add-role-to-instance-profile \
--instance-profile-name $CONTROL_PLANE_PROFILE \
--role-name control-plane-role
Finally, we'll go through a similar process for the node pools: first creating an IAM policy, then attaching it to a role, creating an instance profile, then adding the role to the instance profile:
aws iam create-role --role-name node-pool-role \
--assume-role-policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Service": "ec2.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}'
NODE_POOL_POLICY_ARN=$(aws iam create-policy --policy-name node-pool-policy_kms \
--policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["kms:Decrypt"],
"Resource": "'$KMS_KEY_ARN'"
}
]
}' --output json | jq -r ".Policy.Arn")
aws iam attach-role-policy --role-name node-pool-role \
--policy-arn $NODE_POOL_POLICY_ARN
NODE_POOL_PROFILE=node-pool-profile
aws iam create-instance-profile \
--instance-profile-name $NODE_POOL_PROFILE
aws iam add-role-to-instance-profile \
--instance-profile-name $NODE_POOL_PROFILE \
--role-name node-pool-role
Now we finally have our encryption keys, IAM profiles and roles set up, and we can move onto networking!
AWS Networking
Our GKE clusters will require a dedicated VPC, subnets, internet gateways, routing tables, elastic IPs and NAT gateways to work. There's a lot to get through, so let's get started!
First, the easy bit. We'll create a new VPC with a CIDR of 10.0.0.0/16. Feel free to adjust the region to suit your requirements:
aws --region us-east-1 ec2 create-vpc \
--cidr-block 10.0.0.0/16 \
--tag-specifications 'ResourceType=vpc, Tags=[{Key=Name,Value=gke-cluster-VPC}]'
Next, we'll capture the ID of the VPC, and use it to enable support for DNS and hostnames:
VPC_ID=$(aws ec2 describe-vpcs \
--filters 'Name=tag:Name,Values=gke-cluster-VPC' \
--query "Vpcs[].VpcId" --output text)
aws ec2 modify-vpc-attribute --enable-dns-hostnames --vpc-id $VPC_ID
aws ec2 modify-vpc-attribute --enable-dns-support --vpc-id $VPC_ID
The next step is to create private subnets in our VPC for our control plane nodes. By default, a GKE cluster in AWS is the equivalent of a private cluster, with no direct access to the API permissable via the Internet. We will instead connect to it via GKE’s Connect API, as we’ll see later on. You can create fewer than three subnets in your VPC if you wish, but three are recommended as GKE will create three control plane nodes regardless. Spreading them across three different availability zones gives you better redundancy in the event of any zonal outages.
In this example I'm using us-east-1a, us-east-1b and us-east-1c availability zones and assigning each of them a /24 CIDR block. If you’re using a different region you’ll want to change these availability zones accordingly.
aws ec2 create-subnet \
--availability-zone us-east-1a \
--vpc-id $VPC_ID \
--cidr-block 10.0.1.0/24 \
--tag-specifications 'ResourceType=subnet, Tags=[{Key=Name,Value=gke-cluster-PrivateSubnet1}]'
aws ec2 create-subnet \
--availability-zone us-east-1b \
--vpc-id $VPC_ID \
--cidr-block 10.0.2.0/24 \
--tag-specifications 'ResourceType=subnet, Tags=[{Key=Name,Value=gke-cluster-PrivateSubnet2}]'
aws ec2 create-subnet \
--availability-zone us-east-1c \
--vpc-id $VPC_ID \
--cidr-block 10.0.3.0/24 \
--tag-specifications 'ResourceType=subnet, Tags=[{Key=Name,Value=gke-cluster-PrivateSubnet3}]'
Next we need to create three public subnets. These will be used to provide outbound internet access for the private subnets (once again, you may need to change the availability zones if you’re using a different region).
aws ec2 create-subnet \
--availability-zone us-east-1a \
--vpc-id $VPC_ID \
--cidr-block 10.0.101.0/24 \
--tag-specifications 'ResourceType=subnet, Tags=[{Key=Name,Value=gke-cluster-PublicSubnet1}]'
aws ec2 create-subnet \
--availability-zone us-east-1b \
--vpc-id $VPC_ID \
--cidr-block 10.0.102.0/24 \
--tag-specifications 'ResourceType=subnet, Tags=[{Key=Name,Value=gke-cluster-PublicSubnet2}]'
aws ec2 create-subnet \
--availability-zone us-east-1c \
--vpc-id $VPC_ID \
--cidr-block 10.0.103.0/24 \
--tag-specifications 'ResourceType=subnet, Tags=[{Key=Name,Value=gke-cluster-PublicSubnet3}]'
PUBLIC_SUBNET_ID_1=$(aws ec2 describe-subnets \
--filters 'Name=tag:Name,Values=gke-cluster-PublicSubnet1' \
--query "Subnets[].SubnetId" --output text)
PUBLIC_SUBNET_ID_2=$(aws ec2 describe-subnets \
--filters 'Name=tag:Name,Values=gke-cluster-PublicSubnet2' \
--query "Subnets[].SubnetId" --output text)
PUBLIC_SUBNET_ID_3=$(aws ec2 describe-subnets \
--filters 'Name=tag:Name,Values=gke-cluster-PublicSubnet3' \
--query "Subnets[].SubnetId" --output text)
At this point we’ve just created the subnets, but we haven’t made them public. To do this we need to modify the map-public-ip-on-launch attribute of each subnet:
aws ec2 modify-subnet-attribute \
--map-public-ip-on-launch \
--subnet-id $PUBLIC_SUBNET_ID_1
aws ec2 modify-subnet-attribute \
--map-public-ip-on-launch \
--subnet-id $PUBLIC_SUBNET_ID_2
aws ec2 modify-subnet-attribute \
--map-public-ip-on-launch \
--subnet-id $PUBLIC_SUBNET_ID_3
Next step is to create an internet gateway for the VPC:
aws --region us-east-1 ec2 create-internet-gateway \
--tag-specifications 'ResourceType=internet-gateway, Tags=[{Key=Name,Value=gke-cluster-InternetGateway}]'
INTERNET_GW_ID=$(aws ec2 describe-internet-gateways \
--filters 'Name=tag:Name,Values=gke-cluster-InternetGateway' \
--query "InternetGateways[].InternetGatewayId" --output text)
aws ec2 attach-internet-gateway \
--internet-gateway-id $INTERNET_GW_ID \
--vpc-id $VPC_ID
You're probably wondering at this point why AWS networking is so much harder than Google Cloud! Well guess what, we're not even closed to being done 😂
We now have a ton of groundwork to lay in the form of route tables. We start with our new public subnets, creating routing tables for each an then associating them with the corresponding subnet:
aws ec2 create-route-table --vpc-id $VPC_ID \
--tag-specifications 'ResourceType=route-table, Tags=[{Key=Name,Value=gke-cluster-PublicRouteTbl1}]'
aws ec2 create-route-table --vpc-id $VPC_ID \
--tag-specifications 'ResourceType=route-table, Tags=[{Key=Name,Value=gke-cluster-PublicRouteTbl2}]'
aws ec2 create-route-table --vpc-id $VPC_ID \
--tag-specifications 'ResourceType=route-table, Tags=[{Key=Name,Value=gke-cluster-PublicRouteTbl3}]'
PUBLIC_ROUTE_TABLE_ID_1=$(aws ec2 describe-route-tables \
--filters 'Name=tag:Name,Values=gke-cluster-PublicRouteTbl1' \
--query "RouteTables[].RouteTableId" --output text)
PUBLIC_ROUTE_TABLE_ID_2=$(aws ec2 describe-route-tables \
--filters 'Name=tag:Name,Values=gke-cluster-PublicRouteTbl2' \
--query "RouteTables[].RouteTableId" --output text)
PUBLIC_ROUTE_TABLE_ID_3=$(aws ec2 describe-route-tables \
--filters 'Name=tag:Name,Values=gke-cluster-PublicRouteTbl3' \
--query "RouteTables[].RouteTableId" --output text)
aws ec2 associate-route-table \
--route-table-id $PUBLIC_ROUTE_TABLE_ID_1 \
--subnet-id $PUBLIC_SUBNET_ID_1
aws ec2 associate-route-table \
--route-table-id $PUBLIC_ROUTE_TABLE_ID_2 \
--subnet-id $PUBLIC_SUBNET_ID_2
aws ec2 associate-route-table \
--route-table-id $PUBLIC_ROUTE_TABLE_ID_3 \
--subnet-id $PUBLIC_SUBNET_ID_3
Public subnets also need default routes for the internet gateway:
aws ec2 create-route --route-table-id $PUBLIC_ROUTE_TABLE_ID_1 \
--destination-cidr-block 0.0.0.0/0 --gateway-id $INTERNET_GW_ID
aws ec2 create-route --route-table-id $PUBLIC_ROUTE_TABLE_ID_2 \
--destination-cidr-block 0.0.0.0/0 --gateway-id $INTERNET_GW_ID
aws ec2 create-route --route-table-id $PUBLIC_ROUTE_TABLE_ID_3 \
--destination-cidr-block 0.0.0.0/0 --gateway-id $INTERNET_GW_ID
The final component for the public subnets is a NAT gateway, that will NAT traffic to the private subnets. These gateways require public IP addresses, so first we assign some elastic IPs, one for each gateway, then we create the NAT gateway for each public subnet:
aws ec2 allocate-address \
--tag-specifications 'ResourceType=elastic-ip, Tags=[{Key=Name,Value=gke-cluster-NatEip1}]'
aws ec2 allocate-address \
--tag-specifications 'ResourceType=elastic-ip, Tags=[{Key=Name,Value=gke-cluster-NatEip2}]'
aws ec2 allocate-address \
--tag-specifications 'ResourceType=elastic-ip, Tags=[{Key=Name,Value=gke-cluster-NatEip3}]'
NAT_EIP_ALLOCATION_ID_1=$(aws ec2 describe-addresses \
--filters 'Name=tag:Name,Values=gke-cluster-NatEip1' \
--query "Addresses[].AllocationId" --output text)
NAT_EIP_ALLOCATION_ID_2=$(aws ec2 describe-addresses \
--filters 'Name=tag:Name,Values=gke-cluster-NatEip2' \
--query "Addresses[].AllocationId" --output text)
NAT_EIP_ALLOCATION_ID_3=$(aws ec2 describe-addresses \
--filters 'Name=tag:Name,Values=gke-cluster-NatEip3' \
--query "Addresses[].AllocationId" --output text)
aws ec2 create-nat-gateway \
--allocation-id $NAT_EIP_ALLOCATION_ID_1 \
--subnet-id $PUBLIC_SUBNET_ID_1 \
--tag-specifications 'ResourceType=natgateway, Tags=[{Key=Name,Value=gke-cluster-NatGateway1}]'
aws ec2 create-nat-gateway \
--allocation-id $NAT_EIP_ALLOCATION_ID_2 \
--subnet-id $PUBLIC_SUBNET_ID_2 \
--tag-specifications 'ResourceType=natgateway, Tags=[{Key=Name,Value=gke-cluster-NatGateway2}]'
aws ec2 create-nat-gateway \
--allocation-id $NAT_EIP_ALLOCATION_ID_3 \
--subnet-id $PUBLIC_SUBNET_ID_3 \
--tag-specifications 'ResourceType=natgateway, Tags=[{Key=Name,Value=gke-cluster-NatGateway3}]'
Moving onto the private subnets, each of these will also need a route table. We'll create them, assign the ID to an environment variable, and associate each table with its corresponding subnet:
aws ec2 create-route-table --vpc-id $VPC_ID \
--tag-specifications 'ResourceType=route-table, Tags=[{Key=Name,Value=gke-cluster-PrivateRouteTbl1}]'
aws ec2 create-route-table --vpc-id $VPC_ID \
--tag-specifications 'ResourceType=route-table, Tags=[{Key=Name,Value=gke-cluster-PrivateRouteTbl2}]'
aws ec2 create-route-table --vpc-id $VPC_ID \
--tag-specifications 'ResourceType=route-table, Tags=[{Key=Name,Value=gke-cluster-PrivateRouteTbl3}]'
PRIVATE_SUBNET_ID_1=$(aws ec2 describe-subnets \
--filters 'Name=tag:Name,Values=gke-cluster-PrivateSubnet1' \
--query "Subnets[].SubnetId" --output text)
PRIVATE_SUBNET_ID_2=$(aws ec2 describe-subnets \
--filters 'Name=tag:Name,Values=gke-cluster-PrivateSubnet2' \
--query "Subnets[].SubnetId" --output text)
PRIVATE_SUBNET_ID_3=$(aws ec2 describe-subnets \
--filters 'Name=tag:Name,Values=gke-cluster-PrivateSubnet3' \
--query "Subnets[].SubnetId" --output text)
PRIVATE_ROUTE_TABLE_ID_1=$(aws ec2 describe-route-tables \
--filters 'Name=tag:Name,Values=gke-cluster-PrivateRouteTbl1' \
--query "RouteTables[].RouteTableId" --output text)
PRIVATE_ROUTE_TABLE_ID_2=$(aws ec2 describe-route-tables \
--filters 'Name=tag:Name,Values=gke-cluster-PrivateRouteTbl2' \
--query "RouteTables[].RouteTableId" --output text)
PRIVATE_ROUTE_TABLE_ID_3=$(aws ec2 describe-route-tables \
--filters 'Name=tag:Name,Values=gke-cluster-PrivateRouteTbl3' \
--query "RouteTables[].RouteTableId" --output text)
aws ec2 associate-route-table --route-table-id $PRIVATE_ROUTE_TABLE_ID_1 \
--subnet-id $PRIVATE_SUBNET_ID_1
aws ec2 associate-route-table --route-table-id $PRIVATE_ROUTE_TABLE_ID_2 \
--subnet-id $PRIVATE_SUBNET_ID_2
aws ec2 associate-route-table --route-table-id $PRIVATE_ROUTE_TABLE_ID_3 \
--subnet-id $PRIVATE_SUBNET_ID_3
We're so close! The final stage is to create default routes to the NAT gateways for our private subnets:
NAT_GW_ID_1=$(aws ec2 describe-nat-gateways \
--filter 'Name=tag:Name,Values=gke-cluster-NatGateway1' \
--query "NatGateways[].NatGatewayId" --output text)
NAT_GW_ID_2=$(aws ec2 describe-nat-gateways \
--filter 'Name=tag:Name,Values=gke-cluster-NatGateway2' \
--query "NatGateways[].NatGatewayId" --output text)
NAT_GW_ID_3=$(aws ec2 describe-nat-gateways \
--filter 'Name=tag:Name,Values=gke-cluster-NatGateway3' \
--query "NatGateways[].NatGatewayId" --output text)
aws ec2 create-route --route-table-id $PRIVATE_ROUTE_TABLE_ID_1 \
--destination-cidr-block 0.0.0.0/0 --gateway-id $NAT_GW_ID_1
aws ec2 create-route --route-table-id $PRIVATE_ROUTE_TABLE_ID_2 \
--destination-cidr-block 0.0.0.0/0 --gateway-id $NAT_GW_ID_2
aws ec2 create-route --route-table-id $PRIVATE_ROUTE_TABLE_ID_3 \
--destination-cidr-block 0.0.0.0/0 --gateway-id $NAT_GW_ID_3
Again, hats off to you if you work with AWS networking on a daily basis. I hope you get plenty of paid leave! But seriously, even though there's a ton of foundations to lay here, hopefully you only have to do it once.
Actually, finally, building a cluster in AWS
This is the moment we've been waiting for! Just note that the commands below will reference a lot of the environment variables that were created in the stages above, so make sure these still exist in your terminal session before you proceed. Building the cluster is a two step process - control plane first, then worker nodes.
Let's start with the cluster and its control plane:
gcloud container aws clusters create aws-cluster \
--cluster-version 1.26.2-gke.1001 \
--aws-region us-east-1 \
--location us-east4 \
--fleet-project $PROJECT_ID \
--vpc-id $VPC_ID \
--subnet-ids $PRIVATE_SUBNET_ID_1,$PRIVATE_SUBNET_ID_2,$PRIVATE_SUBNET_ID_3 \
--pod-address-cidr-blocks 10.2.0.0/16 \
--service-address-cidr-blocks 10.1.0.0/16 \
--role-arn $API_ROLE_ARN \
--iam-instance-profile $CONTROL_PLANE_PROFILE \
--database-encryption-kms-key-arn $KMS_KEY_ARN \
--config-encryption-kms-key-arn $KMS_KEY_ARN \
--tags google:gkemulticloud:cluster=aws-cluster
As you can see, there are many different options that we pass into the command. Notably, we can specify a GKE version (1.26.2-gke.1001 in this example). We also need to provide the AWS region to build the cluster in with the --aws-region option, as well as the Google Cloud region where the Connect API should run. This isn’t available in all Google Cloud locations, so in this example, us-east4 is the closest location to our AWS region where the Connect API is available.
GKE will leverage the Multi-cloud API along with the IAM and KMS configuration you have set up in AWS to connect to the AWS API and build the control plane of your cluster. This should take about 5 minutes, after which your cluster should be shown in the GKE Enterprise cluster list in the Google Cloud console. Note that at this point you may see a warning next to the cluster – don't worry, we’ll fix that in a moment.
Next, we build a node pool for our new cluster – this doesn’t happen automatically like when we build a cluster on Google Cloud. To do this we specify a minimum and a maximum number of nodes along with other options such as the root volume size for each virtual machine, and the subnet ID where they should be hosted:
gcloud container aws node-pools create pool-0 \
--location us-east4 \
--cluster aws-cluster \
--node-version 1.26.2-gke.1001 \
--min-nodes 1 \
--max-nodes 5 \
--max-pods-per-node 110 \
--root-volume-size 50 \
--subnet-id $PRIVATE_SUBNET_ID_1 \
--iam-instance-profile $NODE_POOL_PROFILE \
--config-encryption-kms-key-arn $KMS_KEY_ARN \
--ssh-ec2-key-pair gke-key \
--tags google:gkemulticloud:cluster=aws-cluster
If you don't see a green tick next to your cluster on the GKE clusters page, scroll all the way to the right of your new AWS cluster and click the three dots (Google calls this an actions menu). Select Log in and use the option to authenticate with your Google credentials. This authenticates your console session and creates the bridge from GKE to the Kubernetes API and AWS API. After a few moments, you should see a green tick which means your AWS cluster is now being managed by GKE!
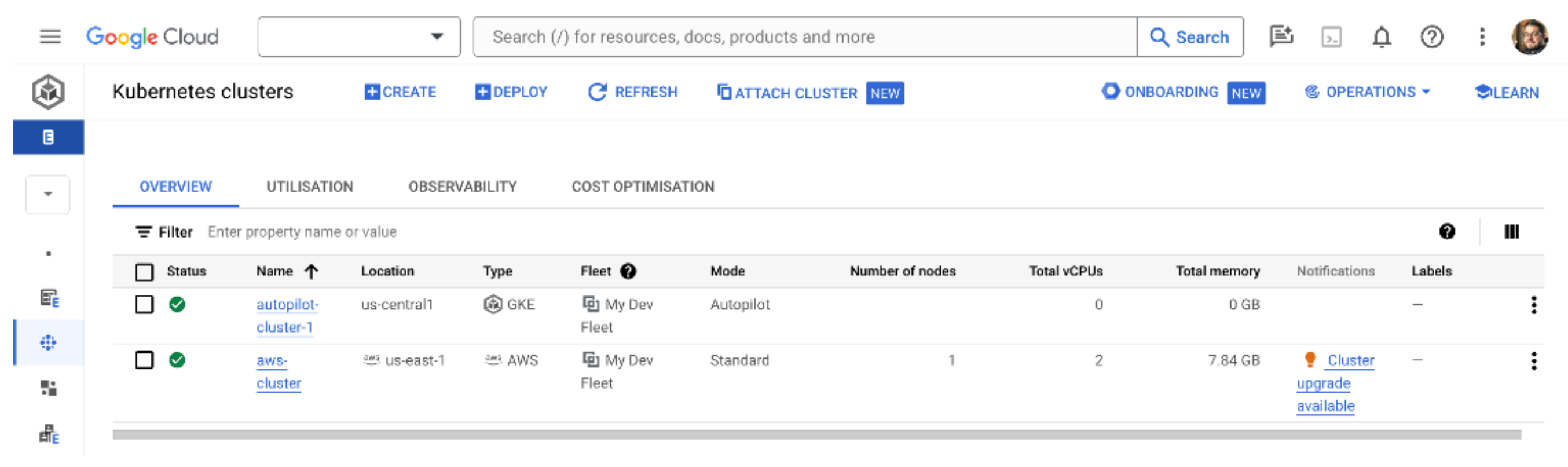
Testing the AWS cluster
Interacting with your new AWS cluster works the same way as if you were working with any other Kubernetes cluster. Even though we've built this cluster in AWS, we're managing it via GKE Enterprise, so we can use gcloud to get credentials for the Kubernetes API and store them in our local kubeconfig file:
gcloud container aws clusters get-credentials aws-cluster --location us-east4
Once you’ve done this, you can issue normal kubectl commands, for example, to see the state of the cluster’s nodes: kubectl get nodes.
Let’s run the following commands to run a test deployment and expose it via a Load Balancer, just like we did with our Google GKE cluster earlier:
kubectl create deployment hello-server --image=us-docker.pkg.dev/google-samples/containers/gke/hello-app:1.0
kubectl expose deployment hello-server --type LoadBalancer --port 80 --target-port 8080
It will take a few minutes for the Load Balancer to get set up. Unlike exposing a Load Balancer service in Google Cloud, our AWS Kubernetes cluster will assign the service a hostname rather than an external IP. You can get the hostname with this command:
kubectl get service hello-server
You should now be able to load the hostname in your browser and see that your deployment is working on AWS! If it doesn’t work straight away, wait a few minutes while AWS configures the Load Balancer and try again.
Deleting the AWS cluster
While deleting a cluster hosted in Google Cloud is quite straightforward, deleting an AWS cluster requires separate steps for the node pools and control plane. Assuming your names and locations match the instructions we followed previously to create the cluster, first delete the node pool with this command:
gcloud container aws node-pools delete pool-0 --cluster aws-cluster --location us-east4
When that command has been completed, we can finally delete the control plane with this command:
gcloud container aws clusters delete aws-cluster --location us-east4
This will delete the EC2 virtual machines that were used to provide the cluster. However...
Deleting other AWS resources
Even though you’ve deleted the EC2 virtual machines, your AWS account will still contain the other resources we created for the VPC and IAM configurations, some of which may continue to incur fees (such as the elastic IP assignments). There’s not enough room in this post to detail how to delete everything, but if you want to be sure that you don’t incur any further charges, walk back through the commands we used to create the resources and remove each resource individually, either using the aws command line or the web console.
Summary
We’ve demonstrated how to build a Kubernetes cluster in AWS that can be managed by GKE, and hopefully you now have a good understanding of the requirements for using GKE in AWS. Google Cloud and AWS are often used together by organisations to provide complementary services, extra redundancy, or availability in different geographic regions, so understanding how to leverage GKE across both vendors should prove very useful.
We're hopefully starting to gain an understanding of the purpose of GKE Enterprise, and what makes it different from working with standard GKE clusters. We learned how the Connect API allows GKE to communicate with other clouds and external Kubernetes clusters, and we started to look at the requirements for building GKE in environments that are external to Google Cloud. GKE guarantees that we are using conformant versions of Kubernetes, so under the hood we always have the same technologies and components to build from, even if a different vendor’s approach to cloud networking requires us to make a few changes. And this is the beauty of using open standards and an open-source project like Kubernetes.
Congratulations if you made it to the end of this very, very long post! 🎉 (Thanks, designers of AWS networking concepts). In the next post, we'll look at how to build GKE Enterprise on bare metal and VMWare environments.