Deploying GKE on Bare Metal and VMWare

This is the third post in a series exploring the features of GKE Enterprise, formerly known as Anthos. GKE Enterprise is an additional subscription service for GKE that adds configuration and policy management, service mesh and other features to support running Kubernetes workloads in Google Cloud, on other clouds and even on-premises. If you missed the first post, you might want to start there.
In my last post of this series I looked at the most common use cases for deploying GKE - running it in the cloud (probably Google Cloud most of the time). Going all in with a single cloud provider was popular in the early boom days of the cloud, but it's now quite common for large enterprises to diversify their IT infrastructure. You may have a requirement to use multiple clouds or, as I’ll cover in this post, your own dedicated physical infrastructure. Use cases for keeping application deployments on-premises or your own managed infrastructure vary but can often be tied to regulatory compliance or the need to guarantee data locality. By using GKE Enterprise, you can keep the same approach to modernisation, the same processes and tools for deployment, and the same level of management and visibility, but have your choice of deployment targets. In this post, I’ll cover how GKE Enterprise enables this by deploying to bare metal, and other customer-managed infrastructure services that may be virtualised (GKE still considers them bare metal if there isn’t a specific cloud solution for them).
I’m going to walk through a demonstration of some principles of bare metal GKE deployments, but I’m going to simulate a physical datacenter using virtual machines in Google’s Compute Engine. There are simply too many different configurations for physical infrastructure for me to try to cover accurately in a blog post, but the concepts should translate to whatever you need to build in your own environments. As I pointed out in previous posts, if you want to try any of this out for yourself, please be mindful of the costs!
Building GKE on Bare Metal Environments
GKE Enterprise refers to bare metal as anything running outside of Google Cloud or other supported cloud vendors, but it’s probably not the best way to describe these non-cloud environments, and indeed Google’s own terminology may be updated in due course to reflect this.
Running GKE Enterprise in this way relies on a solution called Google Distributed Cloud Virtual (GDCV), which is part of the broader Google Distributed Cloud (GDC) service that extends Google Cloud services into alternative data centres or edge appliances. There are even options for GDC that allow you to run a completely isolated and “air-gapped” instance of Google Cloud services on your own hardware! For the purposes of running GKE on bare metal though, we’ll use GDCV to provide connectivity between Google Cloud and other locations such as on-premises data centres.
While many organisations will adopt a cloud-only approach, even if that involves multiple cloud vendors, some organisations may not be ready to fully move to the cloud, or they may have compelling reasons to not do so. This could be due to long-term infrastructure investments in their own data centres, or requirements to work with other types of physical infrastructure. For example, consider industries that work with factories, stadiums, or even oil rigs. Specialised physical infrastructure that is simply not available in the cloud such as bespoke appliances or even mainframes may be in use by some enterprises. An interesting outlier is gaming and gambling companies that are required to generate random numbers in a location that is mandated by law.
Hybrid use-cases
Hybrid computing opens up a world of possibilities for organisations with existing on-premises application deployments, or investments in on-premises infrastructure. Some of these use-cases might include:
Developing and testing applications in a cost-controlled environment on-premises before deploying to a production environment in the cloud
Building front-end and new services in the cloud while keeping enterprise software such as ERP systems on-premises
Storing or processing data in a specific location or under specific controls due to working in a regulated industry
Deploying services to customers in specific areas where no cloud resources are available
Even if you’re deploying to different environments, keeping the process of deploying and managing applications the same will provide developer efficiency, centralised control, and better security. Thankfully, GKE clusters that run in bare metal environments still have most of the capabilities of cloud-based clusters, including integrating with GKE’s management and operations tools, configuration management, and service mesh.
Running GKE on your own servers
Using your own servers – physical or virtual – gives you complete control over the design of your infrastructure, from how your nodes are built to your networking and security configuration. GKE on Bare Metal installs GKE clusters on your own Linux servers and registers them as managed clusters to your GKE Enterprise fleet. And remember, GKE doesn’t care if these really are bare metal, or Linux servers running in a different virtualisation environment.
So, how does this work? With bare metal, there are a few more moving parts than with cloud-based GKE clusters:
User clusters: A Kubernetes cluster where workloads are deployed is now called a user cluster. A user cluster consists of at least one control plane node and one worker node. You can have multiple user clusters, which can operate on physical or virtual machines running the Linux operating system.
Admin cluster: For GKE Bare Metal we also use something called an admin cluster. The admin cluster is a separate Kubernetes control plane that is responsible for the lifecycle of one or more user clusters, and it can create, upgrade, update or delete user clusters by controlling the software that runs on those machines. The admin cluster can also operate on physical or virtual machines running Linux.
Admin workstation: It is recommended to create a separate machine (virtual or physical) to act as an admin workstation, which will contain all the necessary tools and configuration files to manage the clusters. Just like with regular Kubernetes clusters, you’ll use
kubectlas one of these tools to manage workloads on your admin and user clusters. In addition, you’ll use a GKE-specific tool calledbmctlto create, update and administer your clusters.
These are the components that differentiate GKE on Bare Metal from its cloud-based counterparts, but there are many different configurations of clusters to choose from based on your requirements for high availability and resource isolation.
Choosing a deployment pattern
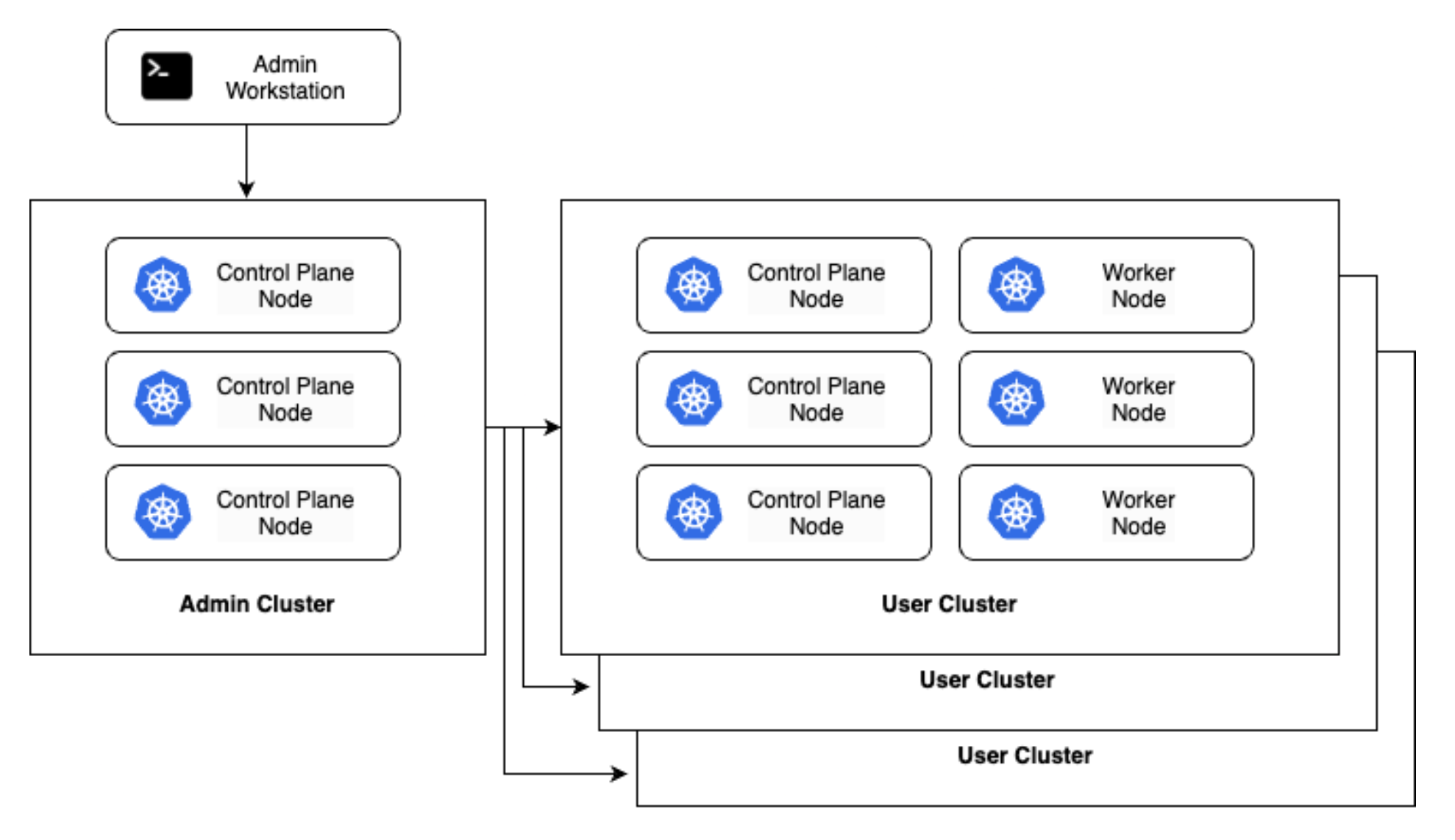
High availability (HA) is recommended for production environments, and it can be achieved by using at least three control plane nodes per cluster (including the admin and user clusters), which we can see illustrated below. This configuration is also recommended when you want to manage multiple clusters in the same datacenter from a single centralised place. Using multiple user clusters allows you to isolate workloads between different environments and teams while keeping a centralised control plane to manage all clusters.
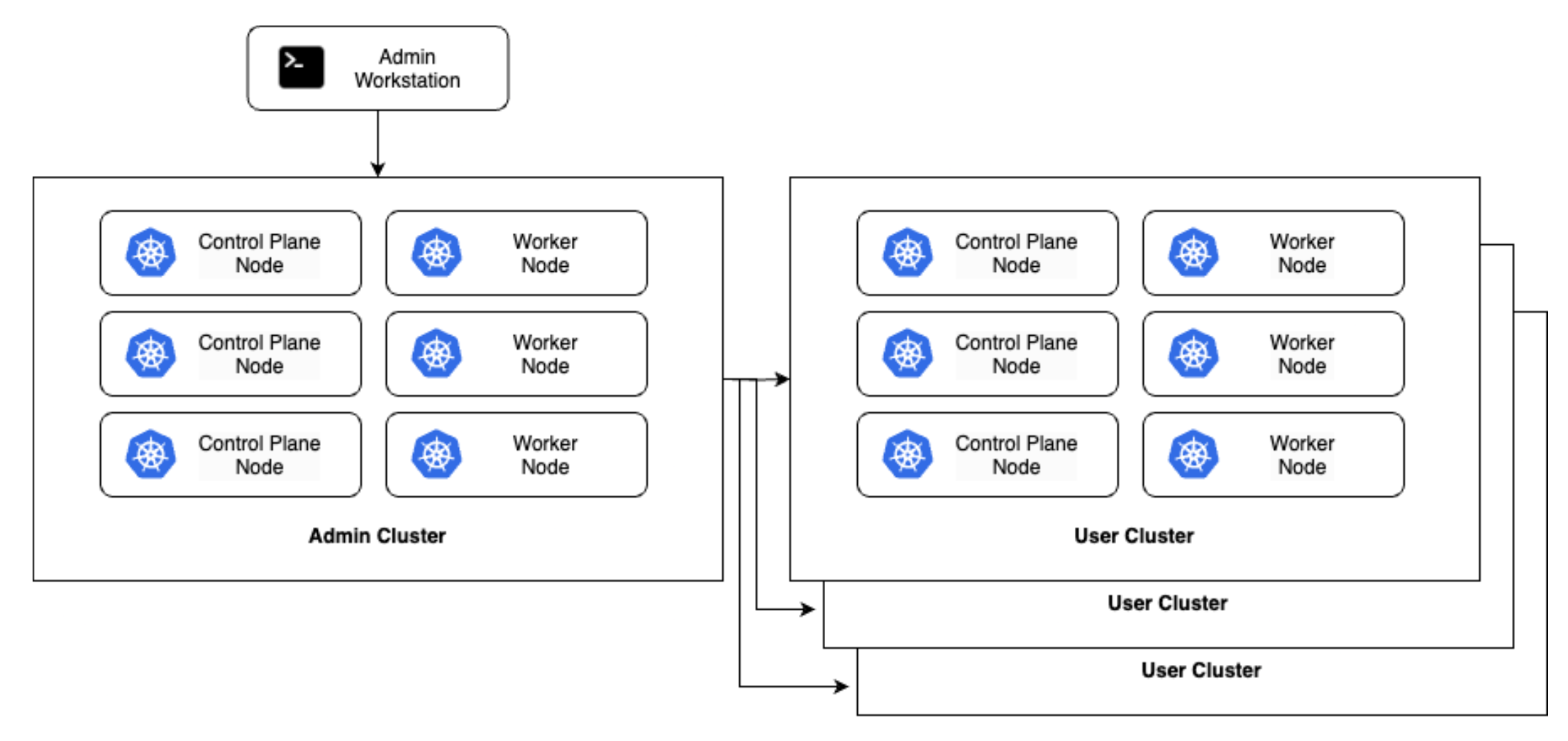
An alternative to this configuration is a hybrid cluster deployment as shown below. In this pattern, admin clusters serve a dual purpose and may also host user workloads in addition to managing user clusters. This can help to reclaim unused capacity and resources from admin clusters that may otherwise be over-provisioned (particularly as in a physical world, as you may have less flexibility around machine size). However, there are risks to this approach, as the admin cluster holds sensitive data such as SSH and service account keys. If a user workload exploits a vulnerability to access other nodes in the cluster, this data could be compromised.
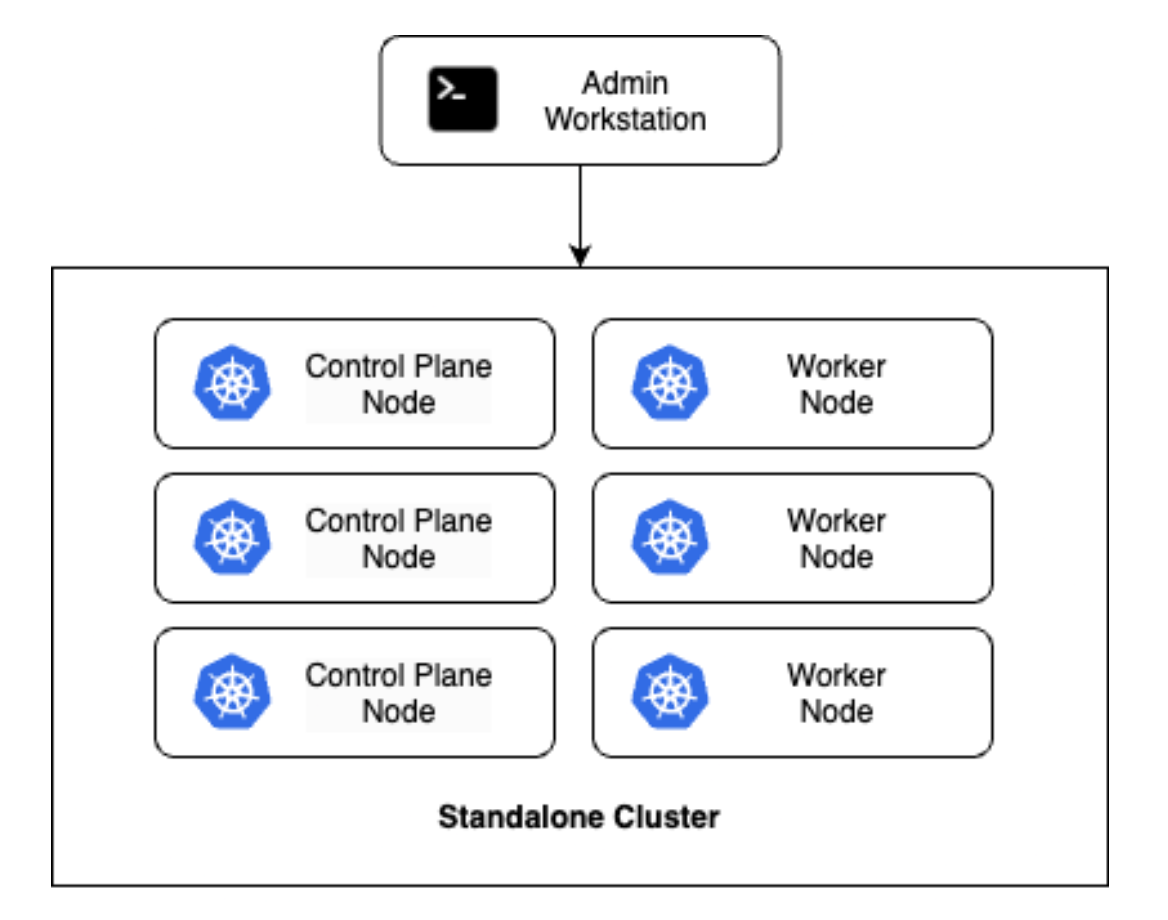
Finally, it is actually possible to run everything you need on a single cluster, essentially taking the hybrid admin cluster from above and removing the separate admin clusters. This can still be HA by having multiple nodes, although everything now runs within a single cluster context which can have the same security risks as the hybrid cluster. The advantage of the standalone cluster, as illustrated below, is that there are significantly fewer resource requirements, which can be helpful in constrained environments or other deployments at the edge.
Network requirements
The networking and connectivity requirements for GKE on Bare Metal can be quite complex and extensive, depending on how your local physical networks are configured, or how you design networks in your own datacenter. I can’t cover all the possible different ways to provide networking for GKE in this post - it would never end! But at a high level you need to consider 3 primary requirements:
Layer 2 and layer 3 networking for cluster nodes
Connectivity to your Google Cloud VPC
How external users will access your workloads
As we know, GKE on Bare Metal runs on physical or virtual machines that you provide; in other words, these machines already exist and will not be provisioned by GKE. They will therefore already be connected to your own network. GKE on Bare Metal supports layer 2 or layer 3 connectivity between cluster nodes. Remember from the OSI model that layer 2 refers to the data link layer, with physical network cards communicating across a single network segment, usually via ethernet connections. Layer 3 is the network layer, which uses the Internet Protocol (IP) to traverse multiple network segments.
There are lots of pros and cons for both approaches, but your local network design will usually determine which option you use. At a high level, layer 2 is sometimes more suitable for smaller clusters with a focus on simplicity or a requirement to bundle the MetalLB load balancer (more on that in a moment!), while layer 3 is recommended for larger deployments where scalability and security are paramount.
Your Kubernetes nodes will each require their own CIDR block so that they can assign unique IP addresses to Pods, and the size of that block will affect the number of Pods that can be scheduled. The minimum size of the CIDR block is a /26 which allows for 64 IP addresses and 32 Pods per node. The maximum CIDR block size is a /23 which allows for 512 IP addresses and the maximum of 250 Pods per node. Again, your local network design will impact this configuration.
Your local nodes will require connectivity to Google Cloud so that they can communicate with the Connect Agent that will facilitate communication between the GKE service and your local Kubernetes API server. You can set up this connectivity either across the public Internet using HTTPS, using a VPN connection or a Dedicated Interconnect. Google has a helpful article on choosing a network connectivity product here: https://cloud.google.com/network-connectivity/docs/how-to/choose-product
Finally, you will need to decide how your external users will connect to your applications hosted on bare metal nodes, if indeed that is a requirement of your clusters. You have a few different options to achieve this, which once again may depend on your local datacenter configuration and your individual requirements.
GKE on Bare Metal can bundle two types of load balancers as part of its deployment. The popular MetalLB bare metal load balancer can be completely managed by GKE for you, providing your cluster nodes run on a layer 2 network. MetalLB load balancers will run on either the control plane nodes of your cluster, or a subset of your work nodes, and provide virtual IPs that are routable through your layer 2 subnet gateway. Services configured with the LoadBalancer type will then be provided with a virtual IP.
Alternatively, GKE on Bare Metal supports a bundled load balancer that uses Border Gateway Protocol (BGP) for nodes on layer 3 networks. This approach provides much more flexibility, but it can be complex to configure. Once again Google provides a complete guide here: https://cloud.google.com/anthos/clusters/docs/bare-metal/latest/how-to/lb-bundled-bgp but I recommend seeking the help of some experienced network engineers to set this up.
Bundled load balancers are just one way to go, however! If your datacenter already runs a load balancing service, such as those provided by F5, Citrix or Cisco, these can also be leveraged. It’s even possible to use cloud load balancers with bare metal servers, however for this to work you must run the ingress service on a cloud-hosted cluster, which then redirects traffic to the on-premises cluster using a multi-cluster ingress. And yes, I’m going to write a post about ingress very soon!
Building some bare metal infrastructure
With the network design out of the way, it’s time to start building our clusters. As mentioned, we’ll be simulating a bare metal environment using Compute Engine just so we can demonstrate the capabilities of GKE on Bare Metal. The tasks we’ll carry out to set up GKE will be almost identical in a real on-premises environment, you’d just be building the servers for real, or using some other kind of infrastructure service. Just like in my last post, you can find the commands below collected into scripts in my Github repo at https://github.com/timhberry/gke-enterprise/tree/main/bare-metal-demo-scripts
For reference, the scripts are:
bm-vpc.sh- Creates a simulated bare metal network using a Google Cloud VPCcreate-servers.sh- Creates and configures multiple virtual machines to act as our bare metal infrastructureadmin-ws-setup.sh- Configures the admin workstationadmin-cluster.sh- Configures the admin cluster (and must be run from the admin workstation)user-cluster.sh- Configures the user cluster (and must be run from the admin workstation)
One final caveat! I just want to reiterate, that below I’m showing you how to build a demo environment using virtual machines in Compute Engine just so we can understand the tooling and the necessary steps to do this on bare metal. So again you’ll need a Google Cloud project with billing enabled, plus the gcloud tool installed and configured. Please be mindful of the costs you’re about to run up, and don’t run GKE for Bare Metal on Compute Engine in production!
Okay, let’s start by creating a VPC for our simulated bare metal environment. We’ll call it baremetal and specify that we’re going to use custom, not auto-assigned subnets. These commands can all be found in the bm-vpc.sh script:
gcloud compute networks create baremetal \
--subnet-mode=custom \
--mtu=1460 \
--bgp-routing-mode=regional
Next we’ll create a subnetwork in the us-central1 region with a CIDR block of 10.1.0.0/24:
gcloud compute networks subnets create us-central1-subnet \
--range=10.1.0.0/24 \
--stack-type=IPV4_ONLY \
--network=baremetal \
--region=us-central1
We’ll create some firewall rules now. First, a rule to allow incoming SSH connections from Google’s Identity Aware Proxy (IAP):
gcloud compute firewall-rules create iap \
--direction=INGRESS \
--priority=1000 \
--network=baremetal \
--action=ALLOW \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20
And then a rule to enable VXLAN traffic for our nodes:
gcloud compute firewall-rules create vxlan \
--direction=INGRESS \
--priority=1000 \
--network=baremetal \
--action=ALLOW \
--rules=udp:4789 \
--source-tags=vxlan
What is this mysterious VXLAN we speak of? Well, even though Google Cloud uses a software-defined network (SDN), we can still simulate a layer 2 network for our bare metal demonstration by using Virtual Extensible LAN (VXLAN) which encapsulates ethernet frames on the layer 3 network. If we were deploying servers on a real layer 2 network, we would not need to perform this step.
A quick side note: In my tests, the VXLAN package and Google Cloud’s SDN did not always play nice. Sometimes these firewall rules were sufficient, sometimes they weren’t. If you get stuck, you can create an “allow all” rule for your pretend bare metal VPC. This is obviously not a secure solution, but this is just for demonstration purposes anyway!
Getting back to our demo, we need to create a service account that we’ll use later for our admin workstation:
PROJECT_ID=$(gcloud config get-value project)
gcloud iam service-accounts create bm-owner
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member=serviceAccount:bm-owner@${PROJECT_ID}.iam.gserviceaccount.com \
--role=roles/owner
Time to create the nodes for our clusters! In this demonstration, we’ll build an admin cluster with a control plane but no worker nodes, and a user cluster with a control plane and one worker node. We won’t go for high availability as this is just a demo, but you can theorise how we could add high availability to this environment by increasing the number of nodes at each level. How you ensure there are no single failure points between multiple nodes depends heavily on how your physical infrastructure is built. These commands can all be found in the create-servers.sh script.
First we’ll create a bash array to hold our server names, and an empty array that will store IP address for us:
declare -a VMs=("admin-workstation" "admin-control" "user-control" "user-worker")
declare -a IPs=()
Now we’ll run a for loop to actually create these servers. To keep things simply, each server is identical. Every time we create a VM, we grab its internal IP and add it to the array:
for vm in "${VMs[@]}"
do
gcloud compute instances create $vm \
--image-family=ubuntu-2004-lts \
--image-project=ubuntu-os-cloud \
--zone=us-central1-a \
--boot-disk-size 128G \
--boot-disk-type pd-standard \
--can-ip-forward \
--network baremetal \
--subnet us-central1-subnet \
--scopes cloud-platform \
--machine-type e2-standard-4 \
--metadata=os-login=FALSE \
--verbosity=error
IP=$(gcloud compute instances describe $vm --zone us-central1-a \
--format='get(networkInterfaces[0].networkIP)')
IPs+=("$IP")
done
Now we need to add some network tags to each instance which will be used by firewall rules we will set up in a moment. Tags are also used to identify which cluster a node belongs to, whether it provides a control plane or a worker, and additionally whether it will double up as a load balancer (which the control planes do). All servers are tagged with the vxlan tag, as we’re about to set up the VXLAN functionality:
gcloud compute instances add-tags admin-control \
--zone us-central1-a \
--tags="cp,admin,lb,vxlan"
gcloud compute instances add-tags user-control \
--zone us-central1-a \
--tags="cp,user,lb,vxlan"
gcloud compute instances add-tags user-worker \
--zone us-central1-a \
--tags="worker,user,vxlan"
For VXLAN to work, we also need to disable the default Ubuntu firewall on each server:
for vm in "${VMs[@]}"
do
echo "Disabling UFW on $vm"
gcloud compute ssh root@$vm --zone us-central1-a --tunnel-through-iap << EOF
sudo ufw disable
EOF
done
That for loop looked really simple didn’t it? Great, because the next one is a lot more complicated 😩 We’ll need to loop through all the VMs and create a VXLAN configuration locally. Doing this assigns an IP address in the 10.200.0.x range for the encapsulated layer 2 network:
i=2
for vm in "${VMs[@]}"
do
gcloud compute ssh root@$vm --zone us-central1-a --tunnel-through-iap << EOF
# update package list on VM
apt-get -qq update > /dev/null
apt-get -qq install -y jq > /dev/null
# print executed commands to terminal
set -x
# create new vxlan configuration
ip link add vxlan0 type vxlan id 42 dev ens4 dstport 4789
current_ip=\$(ip --json a show dev ens4 | jq '.[0].addr_info[0].local' -r)
echo "VM IP address is: \$current_ip"
for ip in ${IPs[@]}; do
if [ "\$ip" != "\$current_ip" ]; then
bridge fdb append to 00:00:00:00:00:00 dst \$ip dev vxlan0
fi
done
ip addr add 10.200.0.$i/24 dev vxlan0
ip link set up dev vxlan0
EOF
i=$((i+1))
done
Once that’s done, we’ll loop through the VMs again and make sure the VXLAN IPs are working:
i=2
for vm in "${VMs[@]}";
do
echo $vm;
gcloud compute ssh root@$vm --zone us-central1-a --tunnel-through-iap --command="hostname -I";
i=$((i+1));
done
The final part of setting up our simulated physical environment is to create the necessary firewall rules that enable traffic to our control planes and worker nodes, as well as inbound traffic to the load balancer nodes and traffic between clusters:
# Add firewall rule to allow traffic to the control plane
gcloud compute firewall-rules create bm-allow-cp \
--network="baremetal" \
--allow="UDP:6081,TCP:22,TCP:6444,TCP:2379-2380,TCP:10250-10252,TCP:4240" \
--source-ranges="10.0.0.0/8" \
--target-tags="cp"
# Add firewal rule to allow inbound traffic to worker nodes
gcloud compute firewall-rules create bm-allow-worker \
--network="baremetal" \
--allow="UDP:6081,TCP:22,TCP:10250,TCP:30000-32767,TCP:4240" \
--source-ranges="10.0.0.0/8" \
--target-tags="worker"
# Add firewall rule to allow inbound traffic to load balancer nodes
gcloud compute firewall-rules create bm-allow-lb \
--network="baremetal" \
--allow="UDP:6081,TCP:22,TCP:443,TCP:7946,UDP:7496,TCP:4240" \
--source-ranges="10.0.0.0/8" \
--target-tags="lb"
gcloud compute firewall-rules create allow-gfe-to-lb \
--network="baremetal" \
--allow="TCP:443" \
--source-ranges="10.0.0.0/8,130.211.0.0/22,35.191.0.0/16" \
--target-tags="lb"
# Add firewall rule to allow traffic between admin and user clusters
gcloud compute firewall-rules create bm-allow-multi \
--network="baremetal" \
--allow="TCP:22,TCP:443" \
--source-tags="admin" \
--target-tags="user"
We’ve now got a completely simulated physical environment, ready for us to set up.
Configuring the admin workstation
The purpose of the admin workstation is to hold the tools and configuration we need to set up and manage our admin and user clusters. We have already created the server itself, but now it’s time to set it up. These commands can be found in the admin-ws-setup.sh script, but if you’re following along, make sure you run all of the commands on the admin workstation itself once you have connected to it.
So first, let’s connect to the workstation using IAP:
eval `ssh-agent`
ssh-add ~/.ssh/google_compute_engine
gcloud compute ssh --ssh-flag="-A" root@admin-workstation \
--zone us-central1-a \
--tunnel-through-iap
Like I said above, everything else for this section should run on the workstation VM itself (not your local machine, or the Cloud Shell terminal for example). Make sure your prompt looks like this:
root@admin-workstation:~#
Okay, first we need to remove the preinstalled snap version of the gcloud SDK, and then install the latest version:
snap remove google-cloud-cli
curl https://sdk.cloud.google.com | bash
exec -l $SHELL
Now we’ll use gcloud to install kubectl:
gcloud components install kubectl
We download Google’s bmctl tool, which simplifies cluster management for bare metal servers, and we install it into /usr/local/sbin:
gsutil cp gs://anthos-baremetal-release/bmctl/1.16.0/linux-amd64/bmctl .
chmod a+x bmctl
mv bmctl /usr/local/sbin/
bmctl version
We also download Docker and install it. Docker will be used to run local containers as part of the installation process for admin and user clusters:
curl -fsSL https://get.docker.com -o get-docker.sh
sh get-docker.sh
docker version
We need to set up an SSH key so that the admin workstation will be able to connect without passwords to each of our nodes. Once again we’ll leverage a bash loops and arrays to copy our SSH public key to each server:
ssh-keygen -t rsa
# Create a bash array containing our server names
declare -a VMs=("admin-control" "user-control" "user-worker")
# Copy our SSH public key to enable password-less access
for vm in "${VMs[@]}"
do
ssh-copy-id -o StrictHostKeyChecking=no -i ~/.ssh/id_rsa.pub root@$vm
done
Finally, we install kubectx. This tool allows us to quickly switch contexts between different Kubernetes clusters:
git clone https://github.com/ahmetb/kubectx /opt/kubectx
ln -s /opt/kubectx/kubectx /usr/local/bin/kubectx
ln -s /opt/kubectx/kubens /usr/local/bin/kubens
That’s it! Our admin workstation is now ready to help us build the rest of our bare metal infrastructure.
Creating the admin cluster
We will now create the admin cluster. In our demo environment, our admin cluster will contain a single control plane node, but no worker nodes, and this single node will also double up as a load balancer. To create the cluster, we’ll need to set up some services and service accounts, then create a configuration file that our admin workstation will use to configure our admin cluster node and turn it into a functioning Kubernetes cluster (albeit a cluster of one!). These commands can be found in the admin-cluster.sh script.
First, we set some environment variables for our project, zone, SSH key and load balancer IP addresses:
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export SSH_PRIVATE_KEY=/root/.ssh/id_rsa
export LB_CONTROLL_PLANE_NODE=10.200.0.3
export LB_CONTROLL_PLANE_VIP=10.200.0.98
Next, we create a key for the service account we created earlier, and make sure we’re using that to authenticate with Google Cloud APIs:
gcloud iam service-accounts keys create installer.json \
--iam-account=bm-owner@$PROJECT_ID.iam.gserviceaccount.com
export GOOGLE_APPLICATION_CREDENTIALS=~/installer.json
Then we create a config file with the bmctl command. This creates a draft configuration file which we’ll edit in a moment, but it also enables all the APIs we need in our project. The config file is a simple YAML file that tells bmctl how to set up our admin cluster:
bmctl create config -c admin-cluster \
--enable-apis \
--create-service-accounts \
--project-id=$PROJECT_ID
Take a look at the file that’s been created for yourself at ~/bmctl-workspace/admin-cluster/admin-cluster.yaml
Now we’ll use the power of sed to change a bunch of things in the draft configuration file. First, we’ll replace the SSH key placeholder with our actual SSH key:
sed -r -i "s|sshPrivateKeyPath: <path to SSH private key, used for node access>|sshPrivateKeyPath: $(echo $SSH_PRIVATE_KEY)|g" bmctl-workspace/admin-cluster/admin-cluster.yaml
Then we’ll change the node type to admin:
sed -r -i "s|type: hybrid|type: admin|g" bmctl-workspace/admin-cluster/admin-cluster.yaml
And finally update the IP addresses for the load balancer and control plane:
sed -r -i "s|- address: <Machine 1 IP>|- address: $(echo $LB_CONTROLL_PLANE_NODE)|g" bmctl-workspace/admin-cluster/admin-cluster.yaml
sed -r -i "s|controlPlaneVIP: 10.0.0.8|controlPlaneVIP: $(echo $LB_CONTROLL_PLANE_VIP)|g" bmctl-workspace/admin-cluster/admin-cluster.yaml
The draft configuration contains a complete NodePool section, but we don’t want that because in the design pattern we’ve chosen, our admin cluster doesn’t have any worker nodes. We can remove this section with the head command:
head -n -11 bmctl-workspace/admin-cluster/admin-cluster.yaml > temp_file && mv temp_file bmctl-workspace/admin-cluster/admin-cluster.yaml
Now we can actually ask bmctl to create the admin cluster (that is, to configure the existing VM):
bmctl create cluster -c admin-cluster
bmctl will use the config file we have edited, then connect to the control plane node and set it up. Bootstrapping, creating the cluster and performing post-flight checks can take up to 20 minutes, so now is a good time to grab a drink!
When the cluster is finally ready, we’ll export the configuration for the admin cluster to kubectx, and then run kubectl get nodes just to make sure we can see the control plane node:
export KUBECONFIG=$KUBECONFIG:~/bmctl-workspace/admin-cluster/admin-cluster-kubeconfig
kubectx admin=.
kubectl get nodes
Finally, we create a Kubernetes service account that we’ll use to connect to the cluster from the Cloud Console. The last line in the script prints the token out:
kubectl create serviceaccount -n kube-system admin-user
kubectl create clusterrolebinding admin-user-binding \
--clusterrole cluster-admin --serviceaccount kube-system:admin-user
kubectl create token admin-user -n kube-system
In the Kubernetes clusters page of the GKE section in the Google Cloud Console, you should now see your “bare metal” admin cluster. Click Connect from the 3 buttons action menu, and select Token as the method of authentication. Then paste in the token that was provided. This cluster can now be managed completely by GKE!
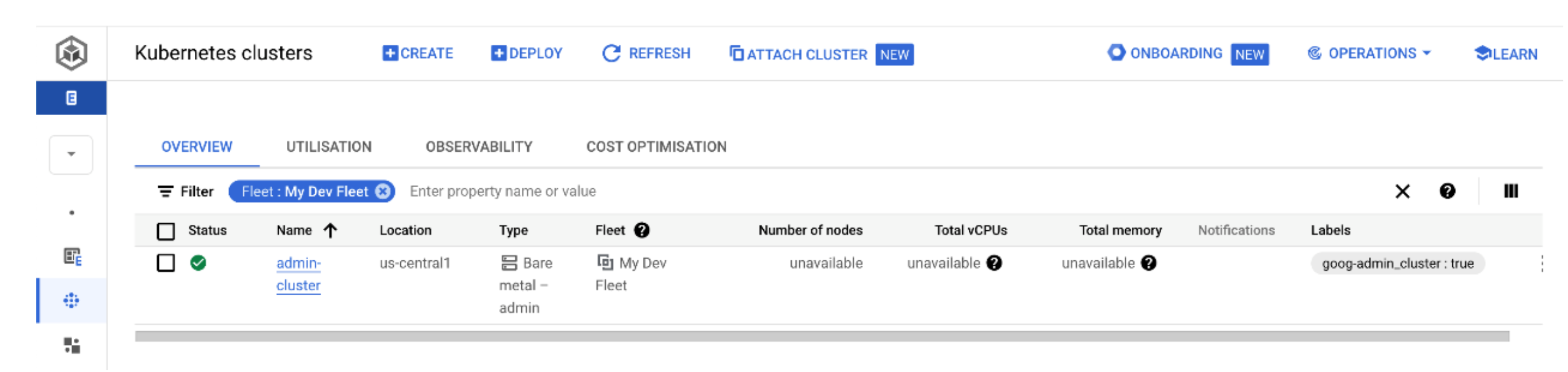
Back on our workstation, we can run kubectl get pods --all-namespaces within the admin cluster context and list all of the different Pods it is running:
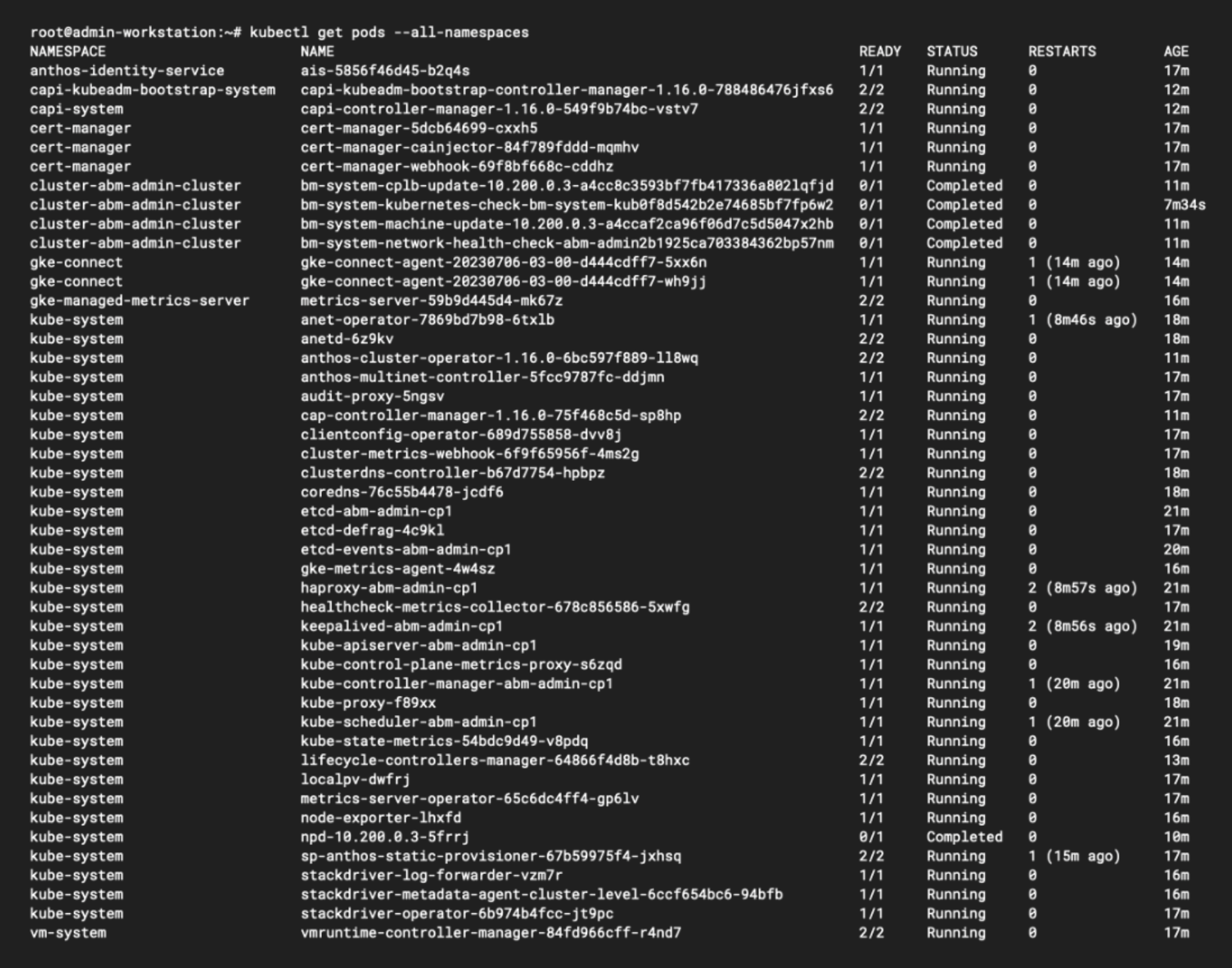
As you can see, the admin cluster is doing quite a bit of heavy lifting. In addition to the usual kube-system Pods, we can see Pods for Stackdriver (the original name of Google’s Operations Suite), and several operators for Anthos (the original name of GKE Enterprise). The Anthos Cluster Operator helps to provision and manage other Kubernetes clusters on physical servers, and the Anthos Multinet Controller is an admission controller for these clusters. You’ll also see the GKE Connect Agent running in its own gke-connect namespace, which facilitates communication between your bare metal clusters and your Google Cloud projects.
Creating a user cluster
Now the admin cluster is built, we go through a similar process for the user cluster, which is where our workloads will run. These steps can be found in the user-cluster.sh script, and once again they should be run from the admin workstation.
Just like before, we use bmctl to create a template configuration file:
bmctl create config -c user-cluster \
--project-id=$PROJECT_ID
The default file references a credentials file we don’t use, so we’ll get rid of that section, and add the path to our private SSH key instead (once again using sed):
tail -n +11 bmctl-workspace/user-cluster/user-cluster.yaml > temp_file && mv temp_file bmctl-workspace/user-cluster/user-cluster.yaml
sed -i '1 i\sshPrivateKeyPath: /root/.ssh/id_rsa' bmctl-workspace/user-cluster/user-cluster.yaml
This is a user cluster, so we’ll change the cluster type:
sed -r -i "s|type: hybrid|type: user|g" bmctl-workspace/user-cluster/user-cluster.yaml
Now we need to set the IP addresses for the control plane node and the API server, a well as the Ingress and LoadBalancer services. Once again sed is our friend:
sed -r -i "s|- address: <Machine 1 IP>|- address: 10.200.0.4|g" bmctl-workspace/user-cluster/user-cluster.yaml
sed -r -i "s|controlPlaneVIP: 10.0.0.8|controlPlaneVIP: 10.200.0.99|g" bmctl-workspace/user-cluster/user-cluster.yaml
sed -r -i "s|# ingressVIP: 10.0.0.2|ingressVIP: 10.200.0.100|g" bmctl-workspace/user-cluster/user-cluster.yaml
sed -r -i "s|# addressPools:|addressPools:|g" bmctl-workspace/user-cluster/user-cluster.yaml
sed -r -i "s|# - name: pool1|- name: pool1|g" bmctl-workspace/user-cluster/user-cluster.yaml
sed -r -i "s|# addresses:| addresses:|g" bmctl-workspace/user-cluster/user-cluster.yaml
sed -r -i "s|# - 10.0.0.1-10.0.0.4| - 10.200.0.100-10.200.0.200|g" bmctl-workspace/user-cluster/user-cluster.yaml
We’ll also enable infrastructure and application logging for the cluster:
sed -r -i "s|# disableCloudAuditLogging: false|disableCloudAuditLogging: false|g" bmctl-workspace/user-cluster/user-cluster.yaml
sed -r -i "s|# enableApplication: false|enableApplication: true|g" bmctl-workspace/user-cluster/user-cluster.yaml
If you recall, we didn’t create a worker node for the admin cluster, we just removed the entire NodePool section. But our user cluster will have a node pool, albeit of just a single additional VM:
sed -r -i "s|name: node-pool-1|name: user-cluster-central-pool-1|g" bmctl-workspace/user-cluster/user-cluster.yaml
sed -r -i "s|- address: <Machine 2 IP>|- address: 10.200.0.5|g" bmctl-workspace/user-cluster/user-cluster.yaml
sed -r -i "s|- address: <Machine 3 IP>|# - address: <Machine 3 IP>|g" bmctl-workspace/user-cluster/user-cluster.yaml
Then we use bmctl create cluster to create the cluster using the updated configuration file. Note that we pass in our existing kubeconfig file so that we can reuse our certificate credentials. It should be slightly quicker for the user cluster to build, but it can still take 10-15 minutes:
bmctl create cluster -c user-cluster --kubeconfig bmctl-workspace/admin-cluster/admin-cluster-kubeconfig
When the cluster is up and running, we’ll create a new kubectx context for it, and use kubectl to make sure both nodes in the cluster are running:
export KUBECONFIG=~/bmctl-workspace/user-cluster/user-cluster-kubeconfig
kubectx user=.
kubectl get nodes
Just like before we will now create a Kubernetes service account that we’ll use in the Cloud Console to log into the cluster:
kubectl create serviceaccount -n kube-system admin-user
kubectl create clusterrolebinding admin-user-binding \
--clusterrole cluster-admin --serviceaccount kube-system:admin-user
And finally, the script will output the token we need to log in via the Console:
kubectl create token admin-user -n kube-system
Back in the Cloud Console you should now see your user cluster. Once again you can click Connect from the 3 buttons action menu, select Token as the method of authentication and paste in the token that was provided. You should now see both of your bare metal clusters - but note that only the user cluster shows that it has any available resources for workloads, which makes sense because it’s the only cluster with worker nodes! (okay, 1 node!)
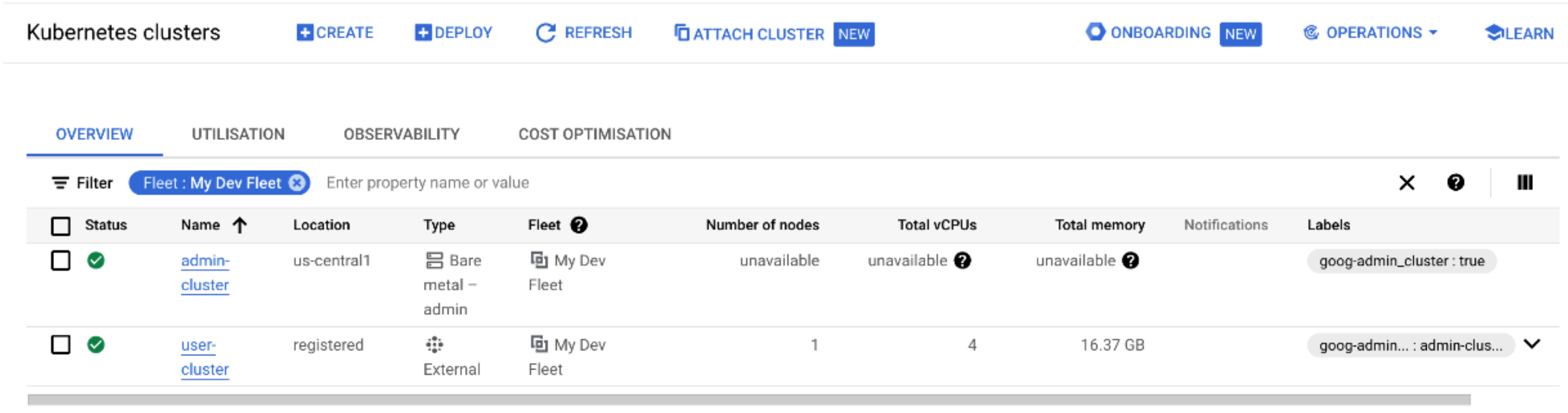
Deploying a test workload
We should now be able to create a test workload and expose it via a load balancer. We’ll use the same demo container as before to create a Hello World deployment. If you’ve been working through the scripts, you should still be logged into the admin workstation and kubectl should be authenticated against your user cluster.
We’ll use kubectl create to create a simple test deployment, followed by kubectl expose to create a service exposed by a load balancer:
kubectl create deployment hello-server --image=us-docker.pkg.dev/google-samples/containers/gke/hello-app:1.0
kubectl expose deployment hello-server --type LoadBalancer --port 80 --target-port 8080
Within a few moments your deployment and service should be up and running. You can get the external IP of the service the usual way:
kubectl get service hello-server
However, this external IP exists only on the overlay network we created with VXLAN. To route to it from the public Internet for example, we’d also have to simulate some sort of external load balancer, which is outside the scope of this post! This is as far as we can go with simulating bare metal, so let's review what we have built:
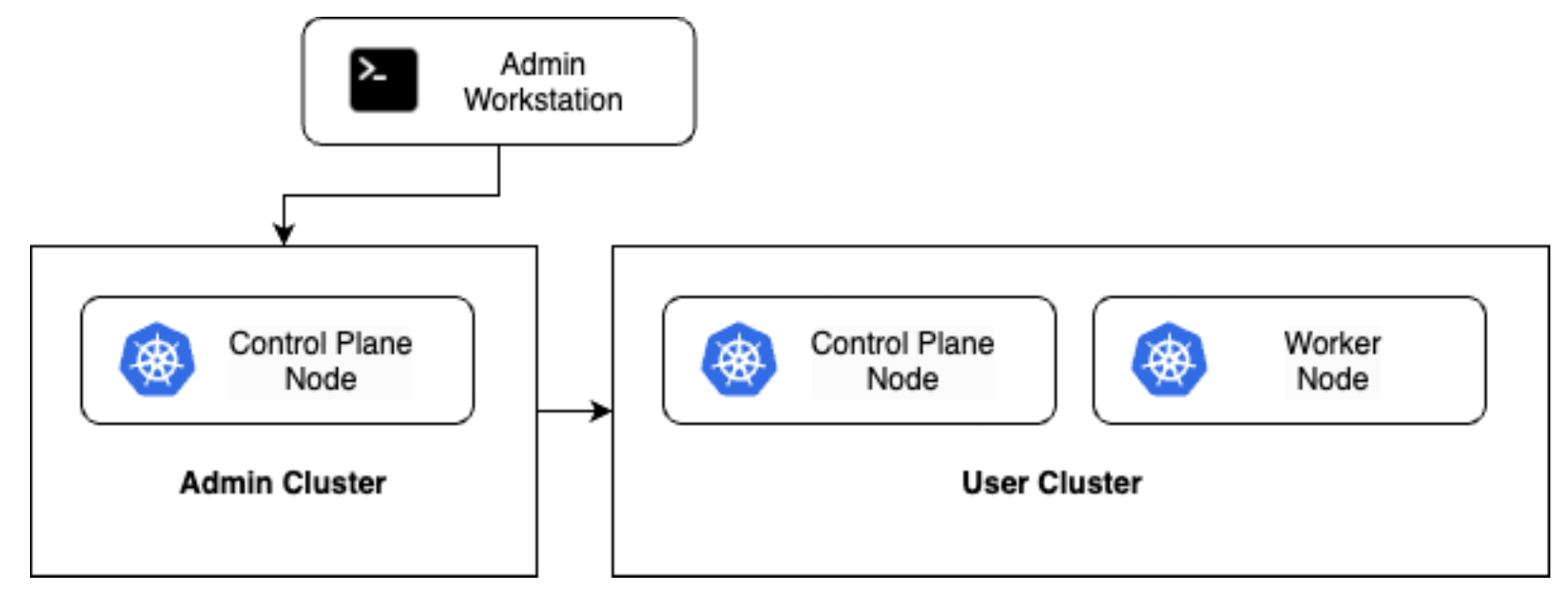
We first set up the admin workstation, which we used as a base to provide the tools and other configuration artifacts we needed.
Then we deployed the admin cluster. This is a special Kubernetes cluster that acts as a management hub for our environment. Even though we issued the
bmctlcommand from our workstation, the admin cluster was instrumental in the creation of the user cluster. The admin cluster is also responsible for communication with your Google Cloud project.Next, we created the user cluster. User clusters are more like the traditional Kubernetes clusters that we know and love, as they are the places that deployed workloads will run.
Just like in our previous demonstrations, we deployed a “Hello World” app to test our new environment.
Even though we've been simulating bare metal, this section has hopefully provided a good overview of the requirements for working with bare metal clusters in your own environments. As we’ve already discussed, there are many scenarios where this hybrid approach is appropriate, and the extra complexity involved should be justified by your use case.
Building GKE on VMWare
If you have existing investments in VMWare, such as a large VMWare estate or significant VMWare skills in your team, it can make sense to continue using these instead of or alongside cloud deployments. Just like with bare metal servers, GKE Enterprise can leverage VMWare to deploy fully managed GKE clusters. Your workloads can be deployed to GKE clusters on VMWare, bare metal or in the cloud with a single developer experience and a centralised approach to management.
GKE Enterprise works with VMWare in a very similar way to the bare metal approach we’ve already described and demonstrated, but with an added integration into the infrastructure automation provided by the VSphere software in VMWare. At a very high level this means that VSphere can automate some of the infrastructure tasks required, such as creating virtual machines, whereas in bare metal scenarios this is normally done manually.
So just like with bare metal, GKE on VMWare comprises the following components:
User clusters to run your containerised workloads. User clusters have one or more control plane nodes and one or more worker nodes, depending on your requirement for high availability.
An admin cluster to manage the user clusters. Again, this can be configured in a high availability pattern if your underlying infrastructure offers redundant points of failure.
An admin workstation to provide the configuration and tooling for building clusters. Our bare metal clusters used the
bmctltool for configuration and cluster building, but we’ll now use the GKE on VMWare tool calledgkectl. This tool uses credentials for VCenter to automate the creation of virtual machines for all clusters, so you don’t have to build them manually.
Let’s walk through a hypothetical build of a GKE environment on VMWare so we can examine some design considerations. Because the overall process is quite similar to GKE on Bare Metal, we won’t be detailing the full installation steps with scripts and commands, we’ll just focus on illustrating what’s different with VMWare. For a full installation guide, see: https://cloud.google.com/kubernetes-engine/distributed-cloud/vmware/docs/overview
Preparing your VMWare environment
At a bare minimum, GKE on VMWare requires at least one physical host running the ESXi hypervisor with 8 CPUs, 80GB or RAM and around half a terabyte of storage. At the time of writing, GKE on VMWare supports ESXi version 7.0u2 or higher and Center Server 7.0u2 or higher. Your vSphere environment requires:
A vSphere virtual datacenter – this is essentially a virtual environment that contains all other configuration objects
A vSphere cluster – although a single node will work, it still needs to be configured as a cluster
A vSphere datastore – this will store the virtual machine files used to provision admin and user clusters for GKE
A vSphere network – essentially a virtual network. There are quite a few network requirements for VMWare, so we’ll get into them below.
Just like GKE on Bare Metal, your VMWare environment will require IP address assignments for all nodes, virtual IPs for control plane components, and dedicated CIDR ranges for Pods and Services. It’s important to plan your IP allocations carefully, and how you do this will vary based on your existing VMWare deployment and other network infrastructure. Planning can also include the use of dynamically assigned IP addresses for nodes using DHCP, as vSphere builds the virtual machines for the clusters for you and can request IP addresses as it does so.
Your admin workstation and your clusters are likely to use IP addresses on your vSphere network, and so are the virtual IPs for the API server and cluster ingress. When you choose CIDR ranges for Pods and Services, it's recommended to use private IP ranges as specified in RFC1918. Typically, you spin up more Pods than Services, so for each cluster it’s recommended to create a Pod CIDR range larger than the Service CIDR range. For example, a user cluster could use the 192.168.0.0/16 block for Pods, and the 10.96.0.0/20 block for Services.
Finally, your clusters will need access to DNS and NTP services, which you may already have running within your VMWare environment.
Creating the admin workstation
Once again, the admin workstation is the first thing we need before building any clusters. This time we don’t need to build a server (or create a VM) manually, because the tooling will do it for us.
First, we download the gkeadm tool. Instructions for downloading the latest version can be found here: https://cloud.google.com/kubernetes-engine/distributed-cloud/vmware/docs/how-to/download-gkeadm
Then we’ll need to create a credentials.yaml file that contains our vCenter login information. Here’s an example:
apiVersion: v1
kind: CredentialFile
items:
- name: vCenter
username: myusername
password: mypassword
Finally, we create a configuration file for the admin workstation. This will contain the details of the vSphere objects we discussed earlier (datacenter, datastore, cluster and network), and the virtual machine specifications used to build the workstation. You can find an example configuration file here: https://cloud.google.com/kubernetes-engine/distributed-cloud/vmware/docs/how-to/minimal-create-clusters#create_your_admin_workstation_configuration_file
Once you’ve populated the configuration file with the details of your own vSphere environment, you can run this command:
gkeadm create admin-workstation --auto-create-service-accounts
The gkeadm tool then accesses vCenter and builds the admin workstation according to the specified configuration. It also sets up any necessary Google Cloud service accounts and creates some template configuration files for admin and user clusters.
Preparing vSphere to build clusters
Once the admin workstation is built, you can log into it and see that it has created some template cluster configurations, as well as service-account key files that will be used for connecting your clusters back to Google Cloud. The admin-cluster.yaml and user-cluster.yaml files contain the details of your vSphere environment, the sizing for cluster nodes, load balancing information and paths to the service accounts that will be used for GKE Connect as well as logging and monitoring.
Once you have edited or reviewed the configuration files, you’ll use the gkectl prepare command, which will check through the config and import the required images to vSphere, marking them as VM templates. Then you can run gkectl create for each cluster, and all of the required virtual machines and other resources will be built for you in your vSphere environment, thanks to gkectl communicating with your vCenter server. Your clusters are automatically enrolled in your GKE Enterprise fleet thanks to the GKE On-Prem API, which means you can manage them in the Google Cloud console or with gcloud commands just like any other GKE cluster.
Summary
In this post, I’ve tried to demonstrate that GKE Enterprise can bring the benefits of a single developer experience and centralised management to Kubernetes clusters running in any environment, not just the cloud. At this point, your GKE fleet might contain clusters running on bare metal, VMWare, Google and AWS all at the same time, and all managed through a single interface! We also looked at some of the networking and other environmental design considerations required for bare metal and walked through a demonstration of a simulated bare metal environment, once again deploying our trusty “Hello World” application.
Thank you for reading this post! I know it’s a long one, but we’ve still barely scratched the surface of what GKE Enterprise can do. In the next post, we’ll get into some of the fun stuff - automation and configuration management.